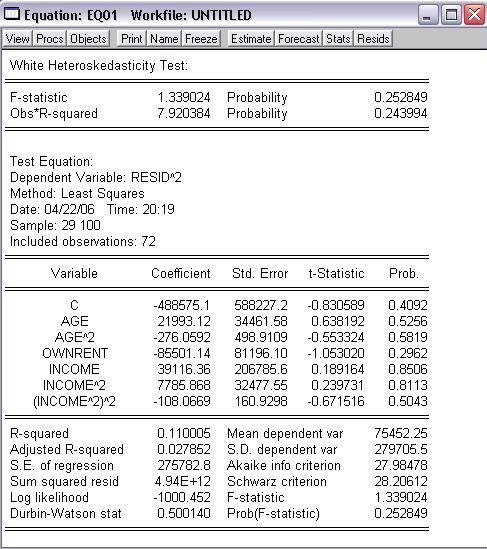
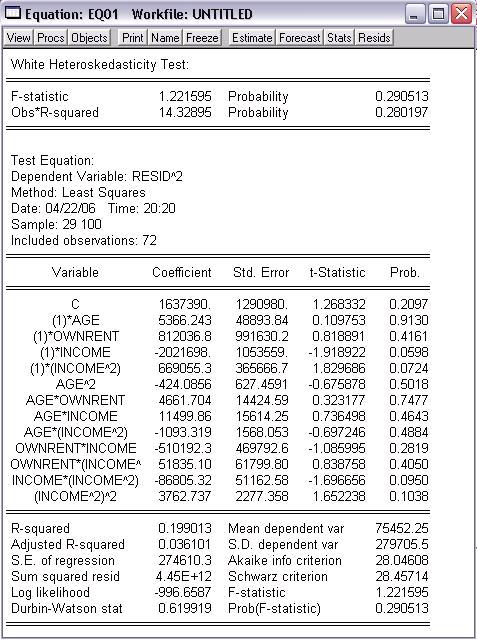
Popis dát (z uvedenej stránky)
Income and Expenditure Data. 100 Cross Section Observations Source: Greene (1992) MDR = Number of derogatory reports Acc = Credit card application accepted (1=yes), Age = Age in years+ 12ths of a year, Income = Income, divided by 10,000 , Avgexp = Avg. monthly credit card expenditure, Ownrent = OwnRent, individual owns (1) or rents (0) home. Selfempl = Self employed (1=yes, 0=no)
Na odhad použijeme iba tie dáta, ktoré majú nenulovú hodnotu premennej avgexp.
Najskôr teda zoradíme dáta podľa premennej Avginc. V menu zvolíme Procs - Sort Series
Zobrazíme usporiadané dáta:
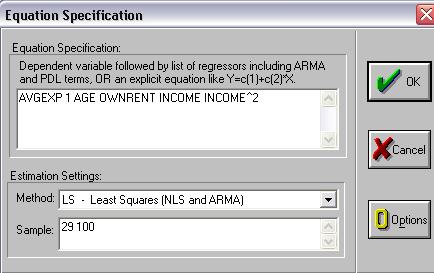
Model
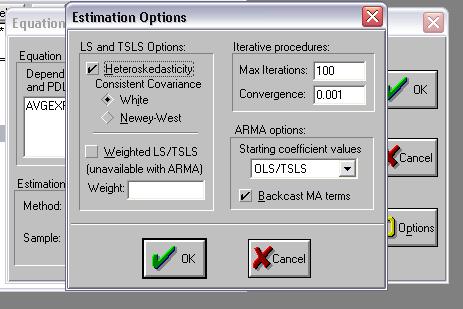
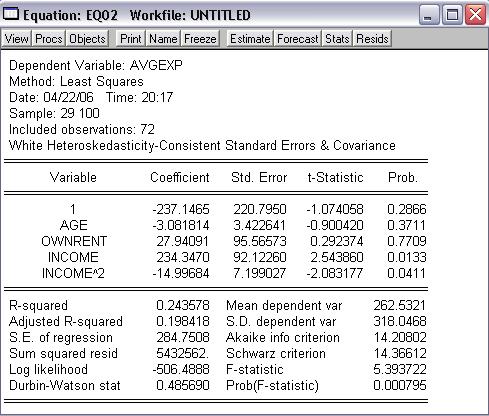
Úprava dát a odhad modelu
Načítame dáta do EVviews. (Postup je na stránke cvičení z predchádzajúceho školského roka: tu.)
Na odhad použijeme iba dáta s nenulovú hodnotou premennej avgexp,
preto zo súboru vylúčime dáta s nulovou hodnotou tejto premennej.
Obr. 1: Zoradenie dát
Obr. 2: Zoradenie dát
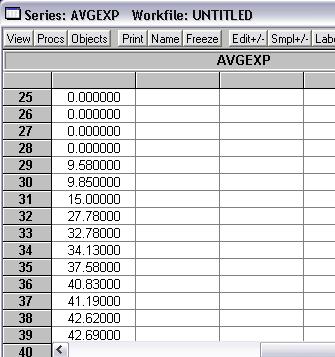
Obr. 3: Zoradené dáta
Obr. 4: Zmena rozsahu dát
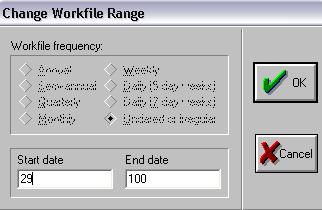
Obr. 5: Zmena rozsahu dát
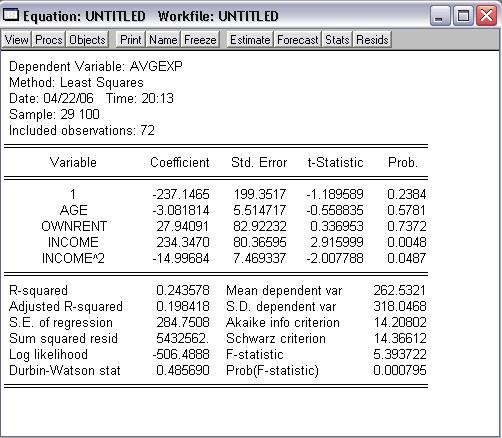
Obr. 6: Regresia
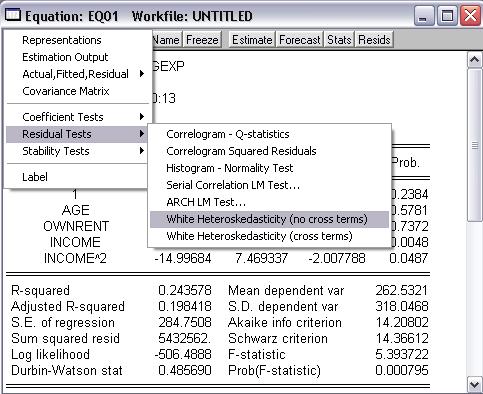
Podozrenie na heteroskedasticitu
Intuitívna prestava o náhodných odchýlkach ε od strednej hodnoty danej vysvetľujúcimi premennými:
Vytvoríme graf, ktorý bude mať na osi x hodnoty premennej, o ktorej si myslíme, že spôsobuje rozdiely vo variancii ε (t.j. income) a na osi y rezíduá.
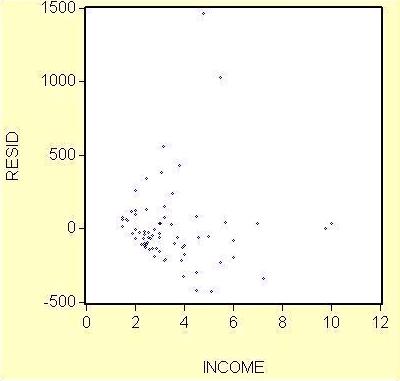
Obr. 7: Graf závislosti rezíduí od premennej income