pocet_poschodi <- 8
pocet_ludi <- 10
set.seed(123) # kvoli reprodukovatelnosti
kde_vystupuju <- sample(1:pocet_poschodi, size = pocet_ludi, replace = TRUE)
kde_vystupuju [1] 7 7 3 6 3 2 2 6 3 5[1] 7 3 6 2 5[1] 5Metódy riešenia úloh z pravdepodobnosti a štatistiky
Do výťahu nastúpilo na prízemí osemposchodovej budovy 10 ľudí. Každý vystupuje s rovnakou pravdepodobnosťou na každom z poschodí, nezávisle od ostatných. Aká je stredná hodnota počtu poschodí, na ktorých výťah zastane, lebo na tomto poschodí niekto vystupuje?
Generovanie vystupovania z výťahu:
pocet_poschodi <- 8
pocet_ludi <- 10
set.seed(123) # kvoli reprodukovatelnosti
kde_vystupuju <- sample(1:pocet_poschodi, size = pocet_ludi, replace = TRUE)
kde_vystupuju [1] 7 7 3 6 3 2 2 6 3 5[1] 7 3 6 2 5[1] 5Princíp simulácií: Zopakujeme takéto generovanie veľa krát a z výsledkov spravíme štatistiku.
pocet_poschodi <- 8
pocet_ludi <- 10
vystupovanie <- function(pocet_poschodi, pocet_ludi){
kde_vystupuju <- sample(1:pocet_poschodi, size = pocet_ludi, replace = TRUE)
kde_zastane <- unique(kde_vystupuju)
pocet_zastaveni <- length(kde_zastane)
return(pocet_zastaveni)
}
set.seed(123)
simulacie <- replicate(10^5, vystupovanie(8, 10))
mean(simulacie)[1] 5.89972Spravíme na cvičení pri tabuli, základná myšlienka:
Očakávame, že priemer zo simulácií sa bude približovať k presnej strednej hodnote.
Zobrazíme priebežné priemery (po 1, 2, 3,… simuláciách):
priebezne_odhady <- cumsum(simulacie)/1:length(simulacie)
head(priebezne_odhady) # zaciatocne hodnoty vektora[1] 5.000000 6.000000 6.333333 6.250000 6.200000 6.500000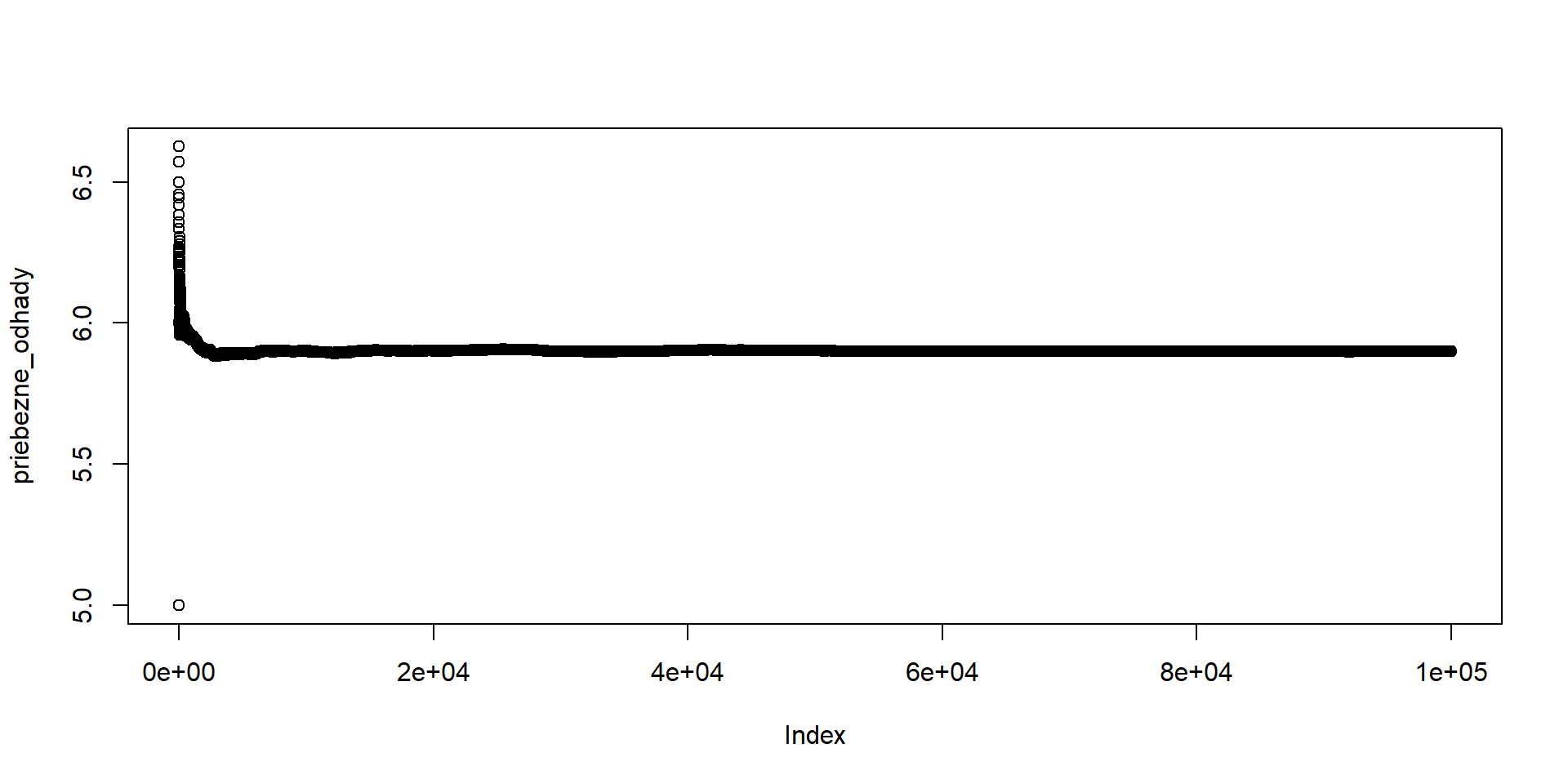
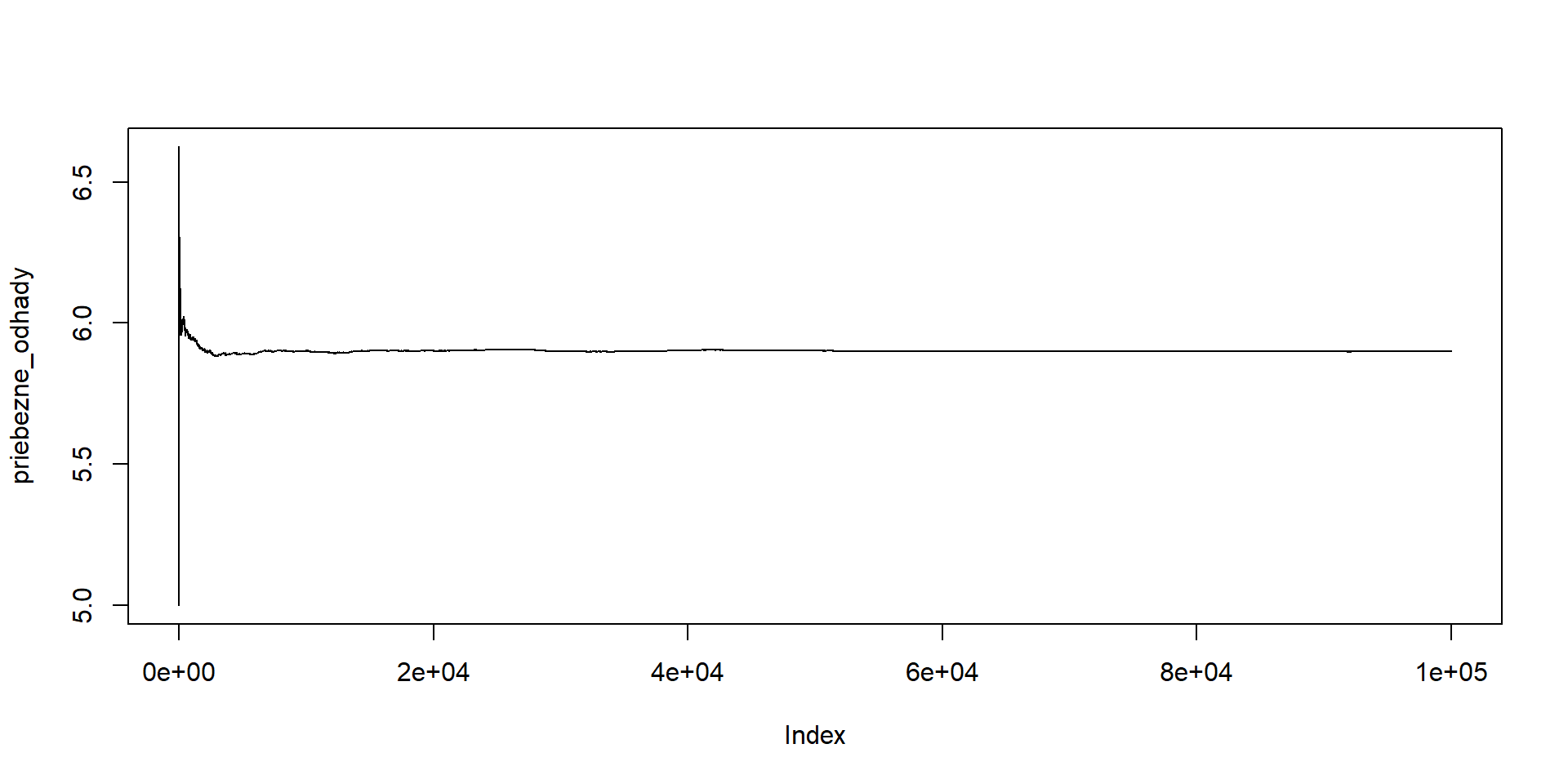
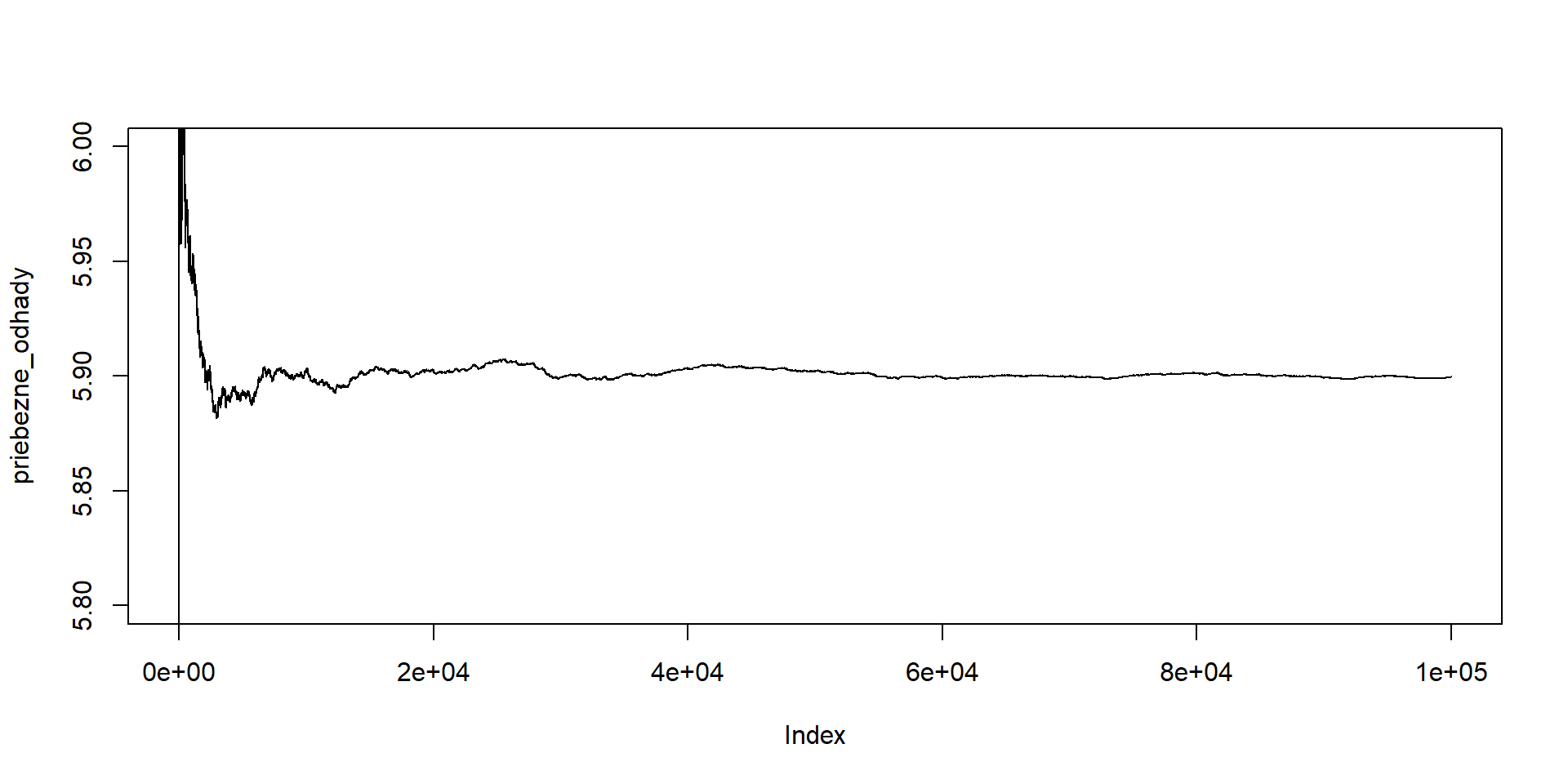
Cvičenie na doma:
[1] 5 7 13 2 10[1] 2 4 6 8 10[1] 16 25 100 4 25[1] FALSE FALSE FALSE FALSE TRUEPríklad A: súčet absolútnych hodnôt prehľadne
Príklad B: súčet absolútnych hodnôt neprehľadne
sucet <- 0
for(i in 1:length(y)){
if(y[i] >=0){
absolutna_hodnota <- y[i]
} else {
absolutna_hodnota <- -y[i]
}
sucet <- sucet + absolutna_hodnota
}
sucet[1] 26Budeme používať funkciu microbenchmark z balíka microbenchmark.
Nainštalovanie balíka:
Načítanie balíka:
Použitie:
Máme k dispozícii funkciu:
function(pocet_poschodi, pocet_ludi){
kde_vystupuju <- sample(1:pocet_poschodi, size = pocet_ludi, replace = TRUE)
kde_zastane <- unique(kde_vystupuju)
pocet_zastaveni <- length(kde_zastane)
return(pocet_zastaveni)
}
Cvičenie: Napíšte funkciu odhad_strednej_hodnoty, ktorá na základe \(10^5\) simulácií odhadne strednú hodnotu počtu poschodí, na ktorých niekto vystúpi v osemposchodovej budove, ak zadáme počet ľudí nastupujúcich do výťahu.
Niektoré funkcie vedia pracovať s vektorovým vstupom:
x <- seq(from = -3*pi, to = 3*pi, by = 0.001) # dalsi sposob vytvorenia vektora
y <- 2*sin(2*x) + 3*cos(5*x)
plot(x, y, type = "l")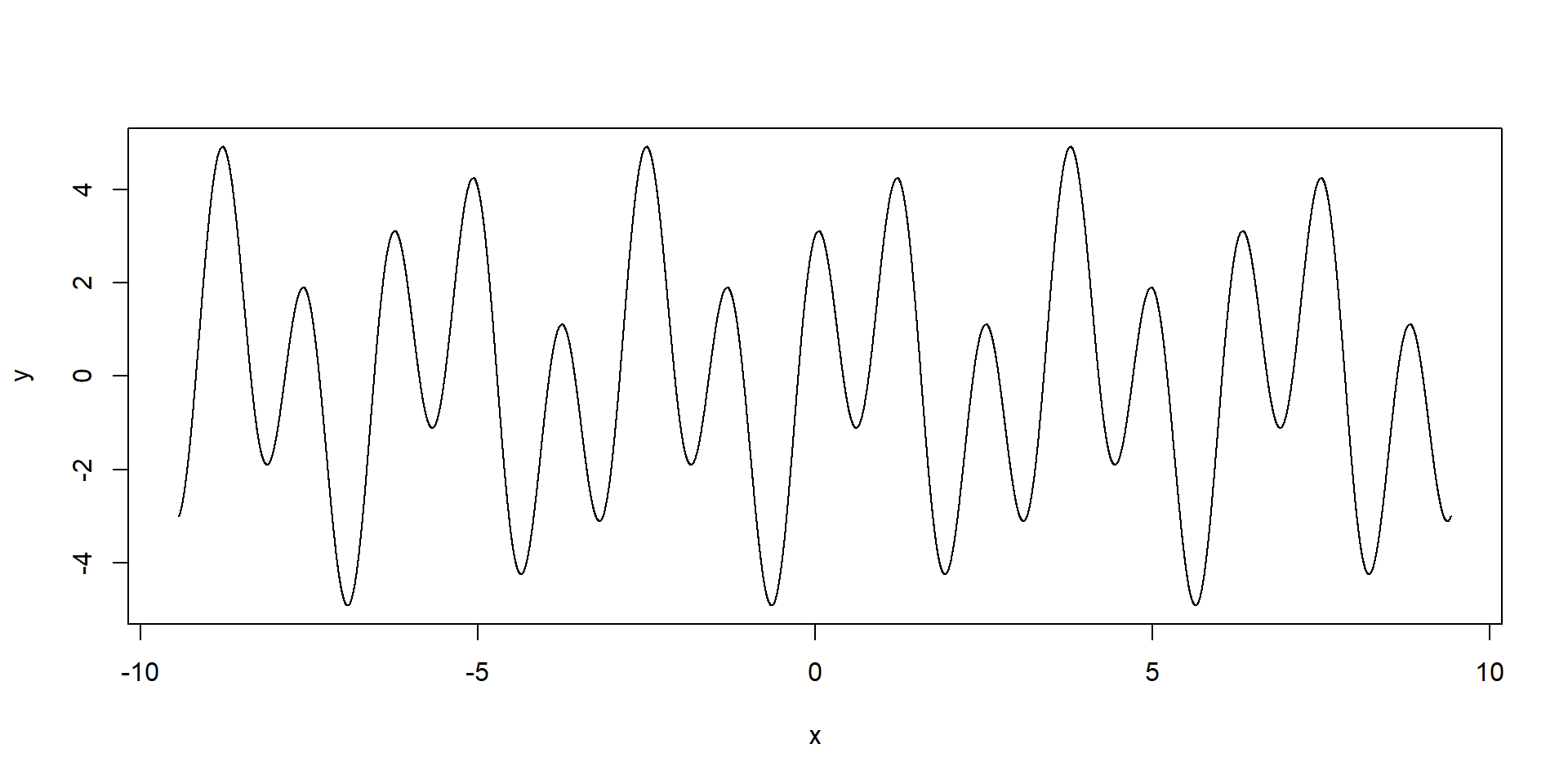
f <- function(t, a, b) a*sin(2*t) + b*cos(5*t)
# ak je vam to prehladnejsie, mozete pisat aj
# plot(t, f(x, a = -2, b = 3), type = "l")
plot(x, f(x, -2, 3), type = "l")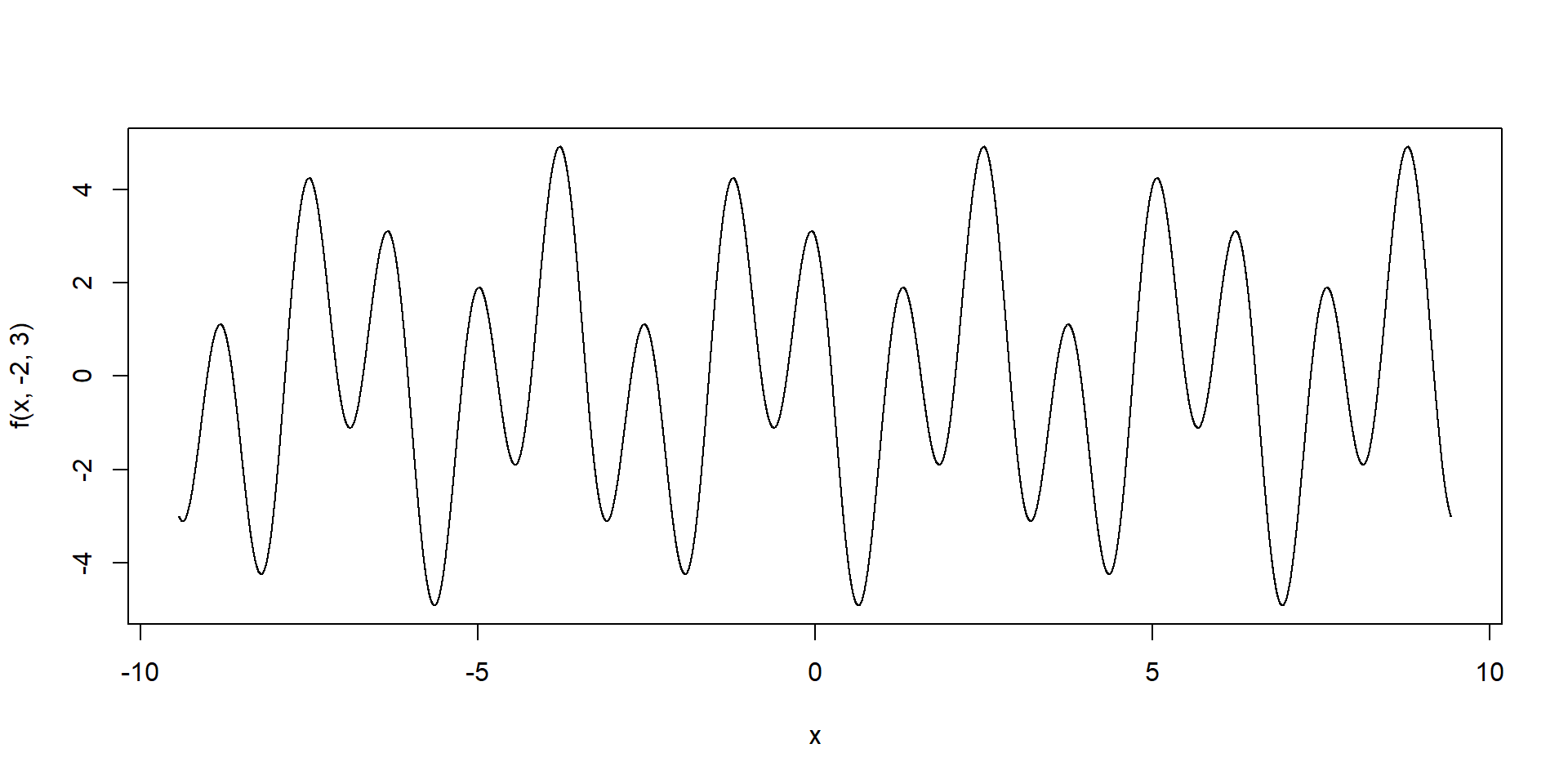
Ale napríklad:
apply = použitie nejakej funkcie pre zadané vstupys = simplify, výstup sa zjednoduší, v tomto príklade na vektorAk 10 ľudí vystupuje na poschodiach osemposchodového domu, počet poschodí, na ktorých niekto vystúpil, nadobúda celočíselné hodnoty medzi 1 a 8. Chceme odhadnúť pravdepodobnosti jednotlivých možností.
Pripomeňme si simulácie:
Funkcia table vytvorí tabuľku s početnosťami:
simulacie
2 3 4 5 6 7 8
5 276 5291 26566 42759 22238 2865 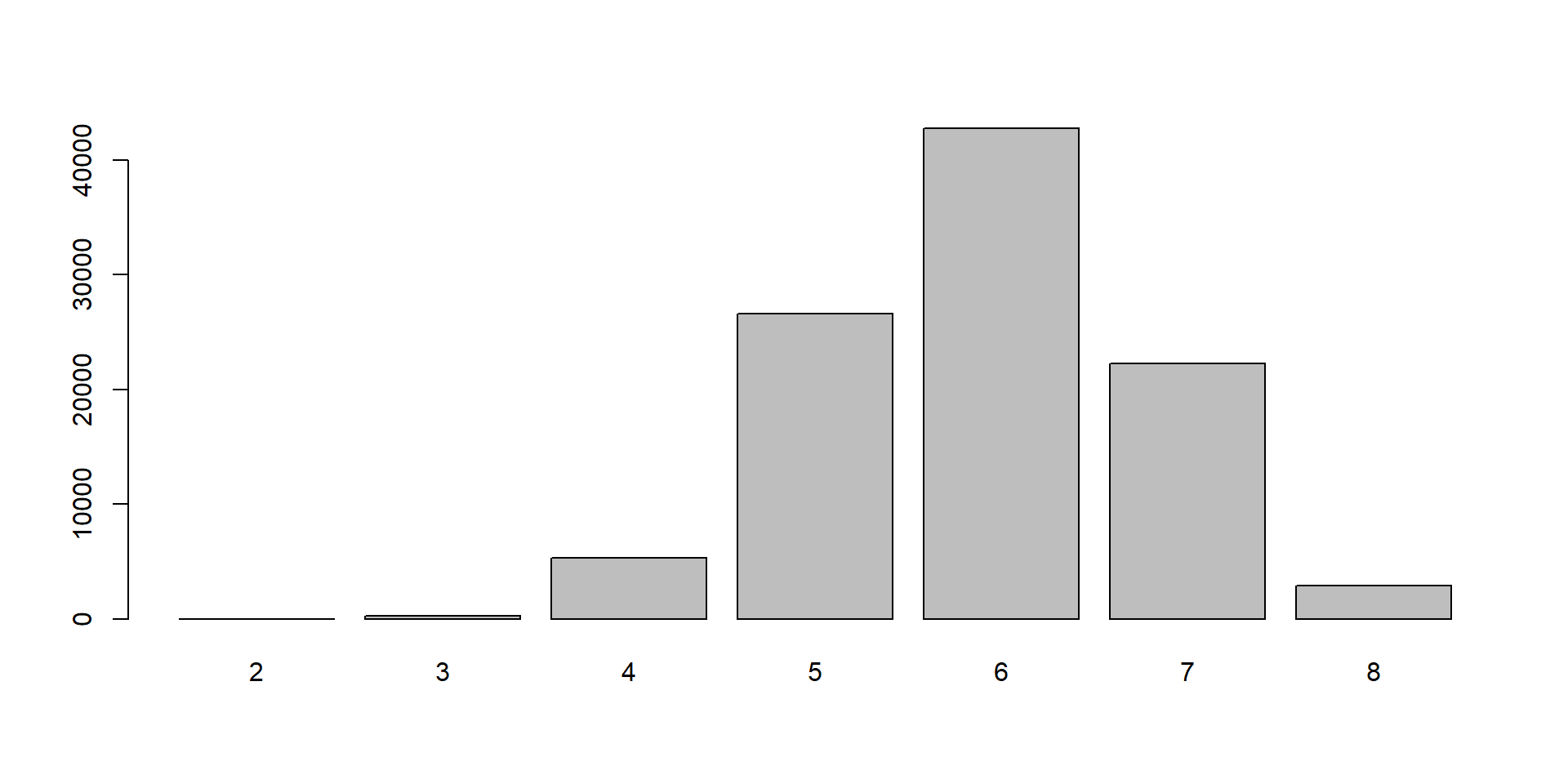
Hodnota 1 sa nerealizovala (má príliš malú pravdepodobnosť), ale chceli by sme ju mať zaradenú do tabuľky s informáciou o nulovom počte výskytov.
simulacie
1 2 3 4 5 6 7 8
0 5 276 5291 26566 42759 22238 2865 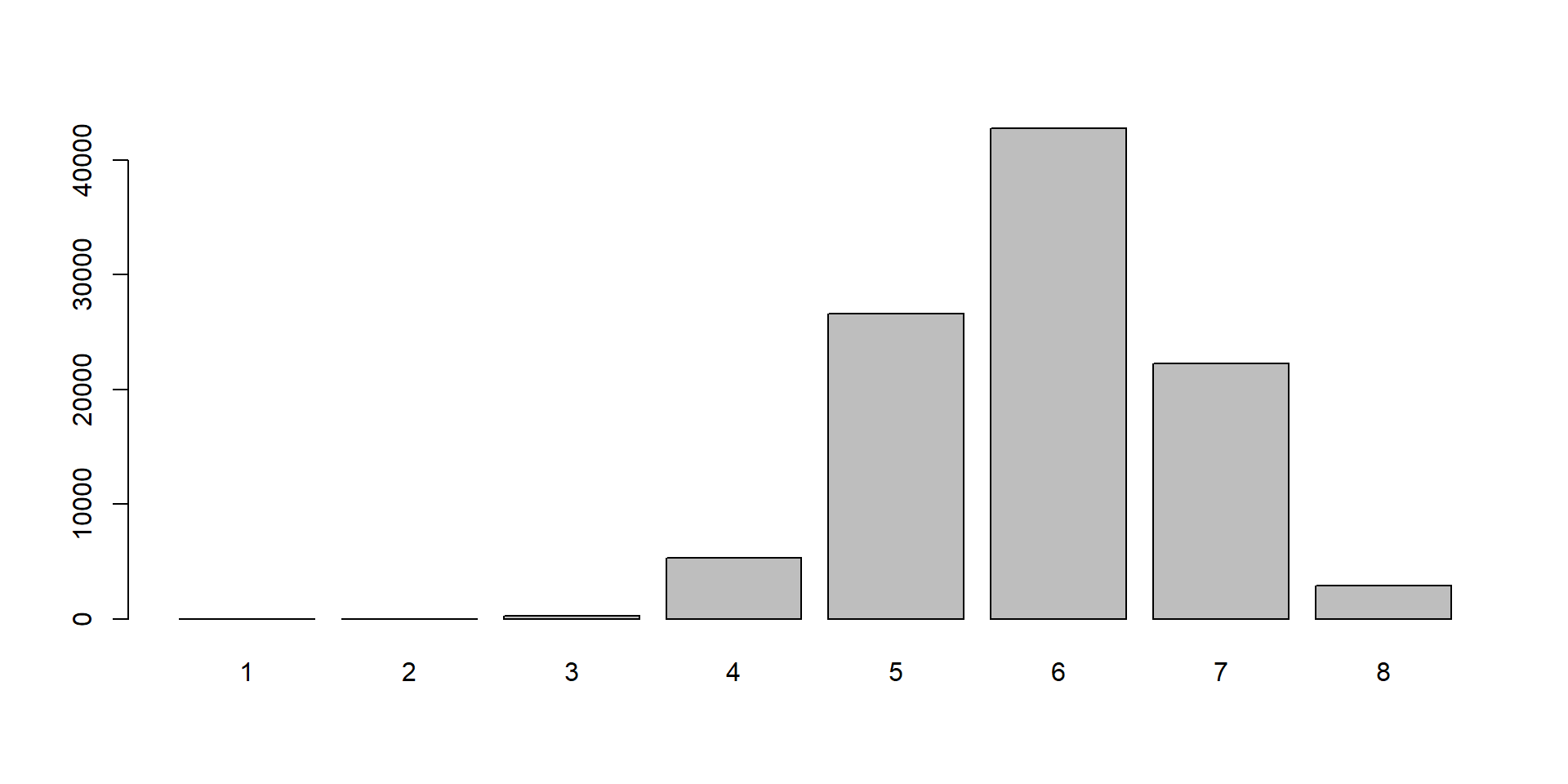
Ak chceme odhady pravdepodobnosť (teda relatívne početnosti), použijeme funkciu prop.table. Jej vstupom je tabuľka vytvorená funkciou table.
Marilyn vos Savant bola istý čas v Guinessovej knihe rekordov ako človek s najvyšším IQ. V rubrike Ask Marilyn odpovedala na rôzne otázky
Niektoré z nich boli matematické úlohy:
A high school student who hadn’t opened his American history book in weeks was dismayed to walk into class and be greeted with a pop quiz. It was in the form of two lists, one naming the 24 presidents in office during the 19th century in alphabetical order and another list noting their terms in office, but scrambled. The object was to match the presidents with their terms. The completely clueless student had to guess every time. On average, how many did he guess correctly?
Predpoklady:
Predpokladajme, že jeho tipovanie odpovedí vyzerali tak, že každému prezidentovi priradil iné obdobie a každé takéto priradenie má rovnakú pravdepodobnosť.
Namiesto 24 prezidentov budeme uvažovať všeobecnú verziu takéhoto testu s tipovania odpovedí s \(n\) položkami.
Zadania:
Odhadnite strednú hodnotu počtu správnych odpovedí v písomke s prezidentami.
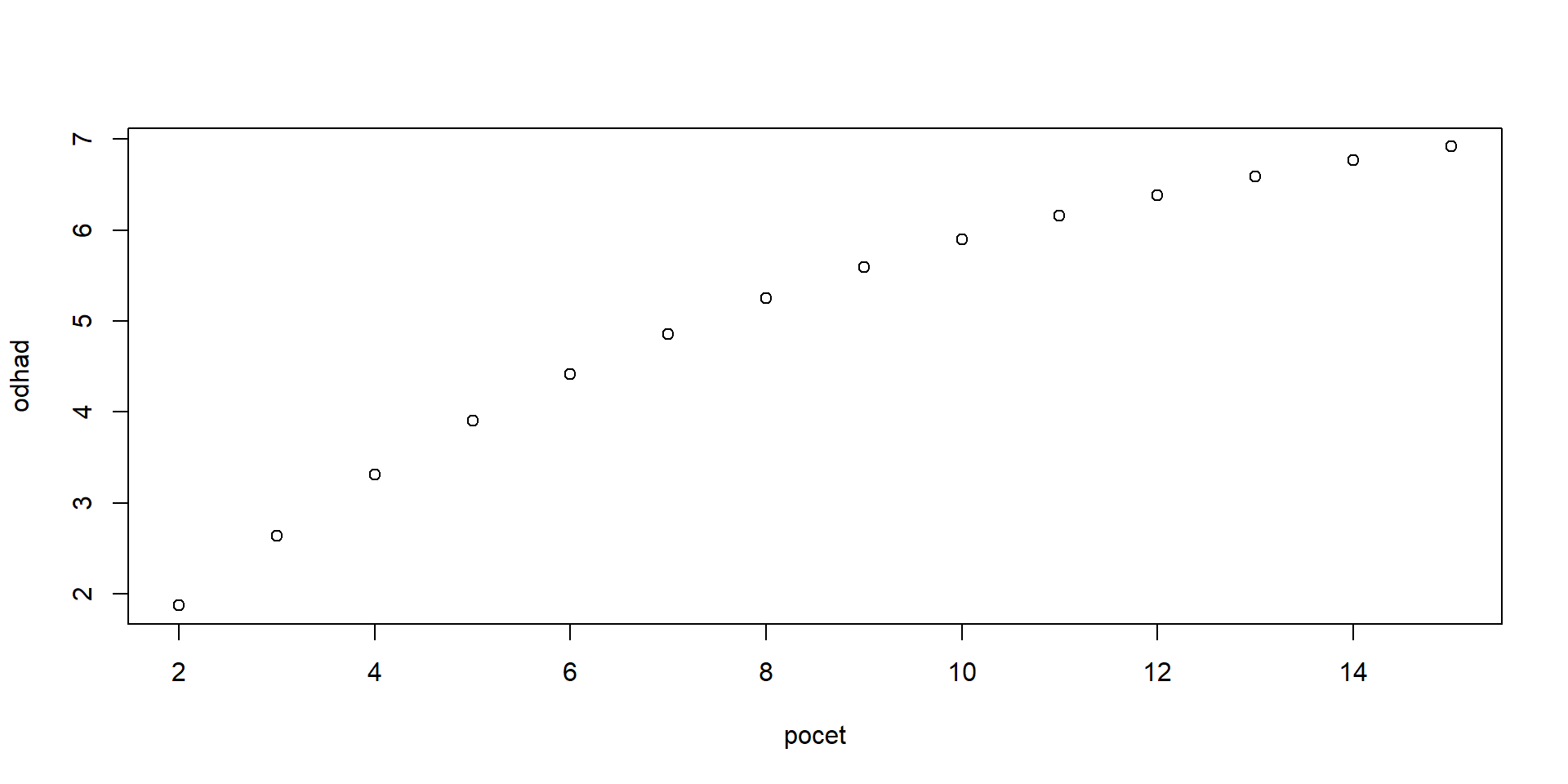
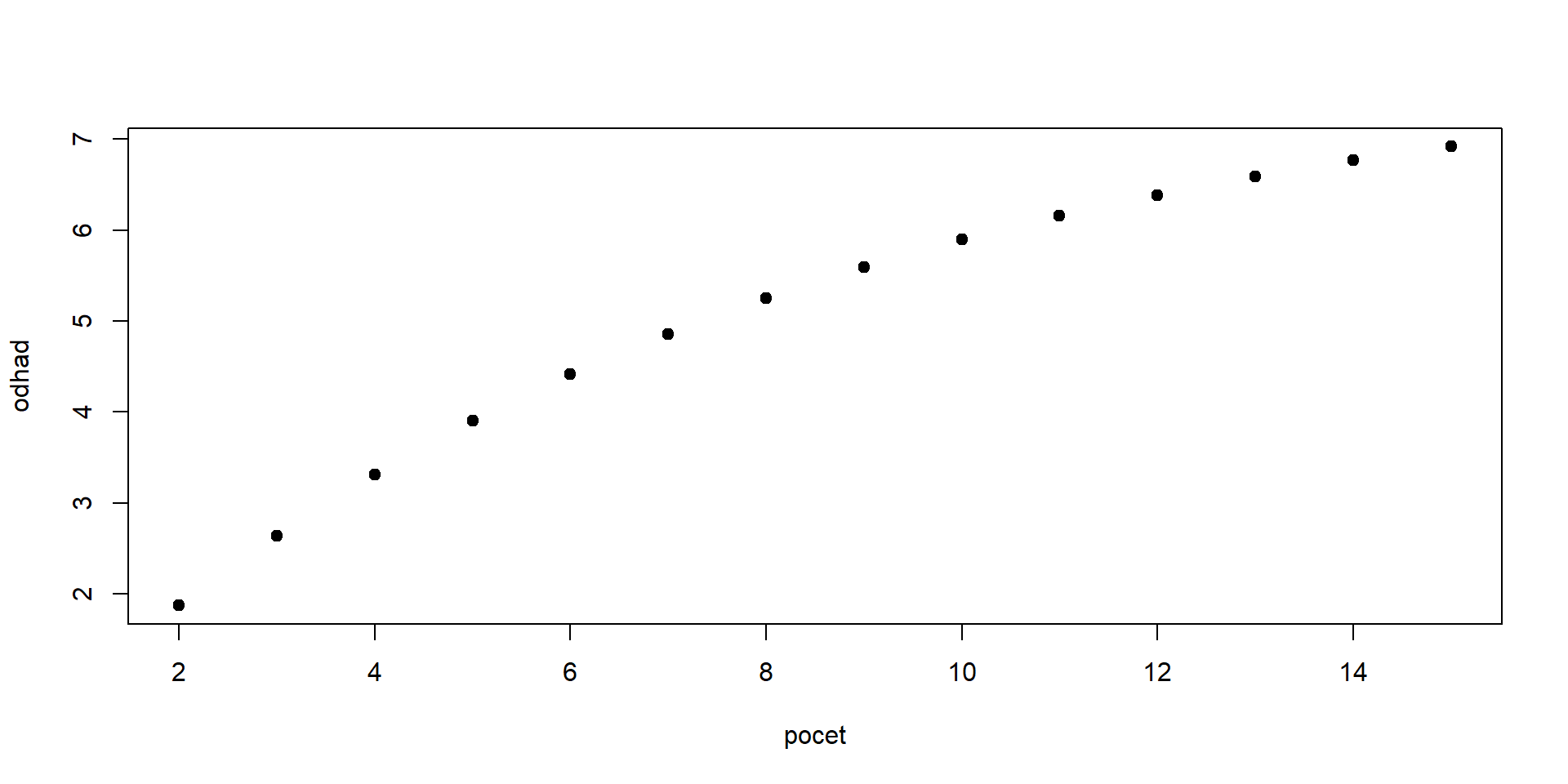
Odhadnite závislosť strednej hodnotu počtu správnych odpovedí od počtu otázok \(n\).
Vyslovte na základe tohto výsledku hypotézu o strednej hodnote a dokážte ju. Návod: definujte náhodné premenné \(X_i\) s hodnotami 0 a 1, ktoré vyjadrujú, či bola i-ta odpoveď správna.
Odhadnite pravdepodobnosti počtu správnych odpovedí a zobrazte ich graficky pre písomku s 10 položkami. Pravdepodobnosti znázornite pre všetky celé čísla medzi 0 a 10 (vrátane toho, ktoré má nulovú pravdepodobnosť - ktoré to je a prečo?)
Uvažujme rýchlu písomku tohto typu, v ktorej treba priradiť literárne diela k autorom, pričom obsahuje 5 položkami (všetci autori aj názvy diel sú rôzni). Za každú správnu odpoveď dostane študent jeden bod, za nesprávnu mínus jeden bod. Potrebuje získať kladný počet bodov. Aká je pravdepodobnosť, že sa mu to pri tejto stratégii podarí?
Ako sa zmení pravdepodobnosť z predchádzajúcej otázky, ak písomka obsahuje len 4 položky?
V písomke s piatimi položkami má Hviezdoslav dve diela (a teda v zozname autorov je dvakrát). Aká je pravdepodobnosť, že študent bude mať kladný počet bodov? (Na voľbu náhodnej permutácie to nemá vplyv, študent automaticky volí náhodné priradenie bez toho, aby vôbec čítal zadanie.)
Máme \(n\) párov ponožiek. Zamiešame ich a vyberáme ich postupne bez toho, aby sme sa na ne pozerali. Ak vyberieme ponožku, ktorej pár sme už vybrali predtým, odložíme ich obidve nabok. Aká je stredná hodnota počtu nájdených párov po tom, čo sme vybrali \(k\) ponožiek?