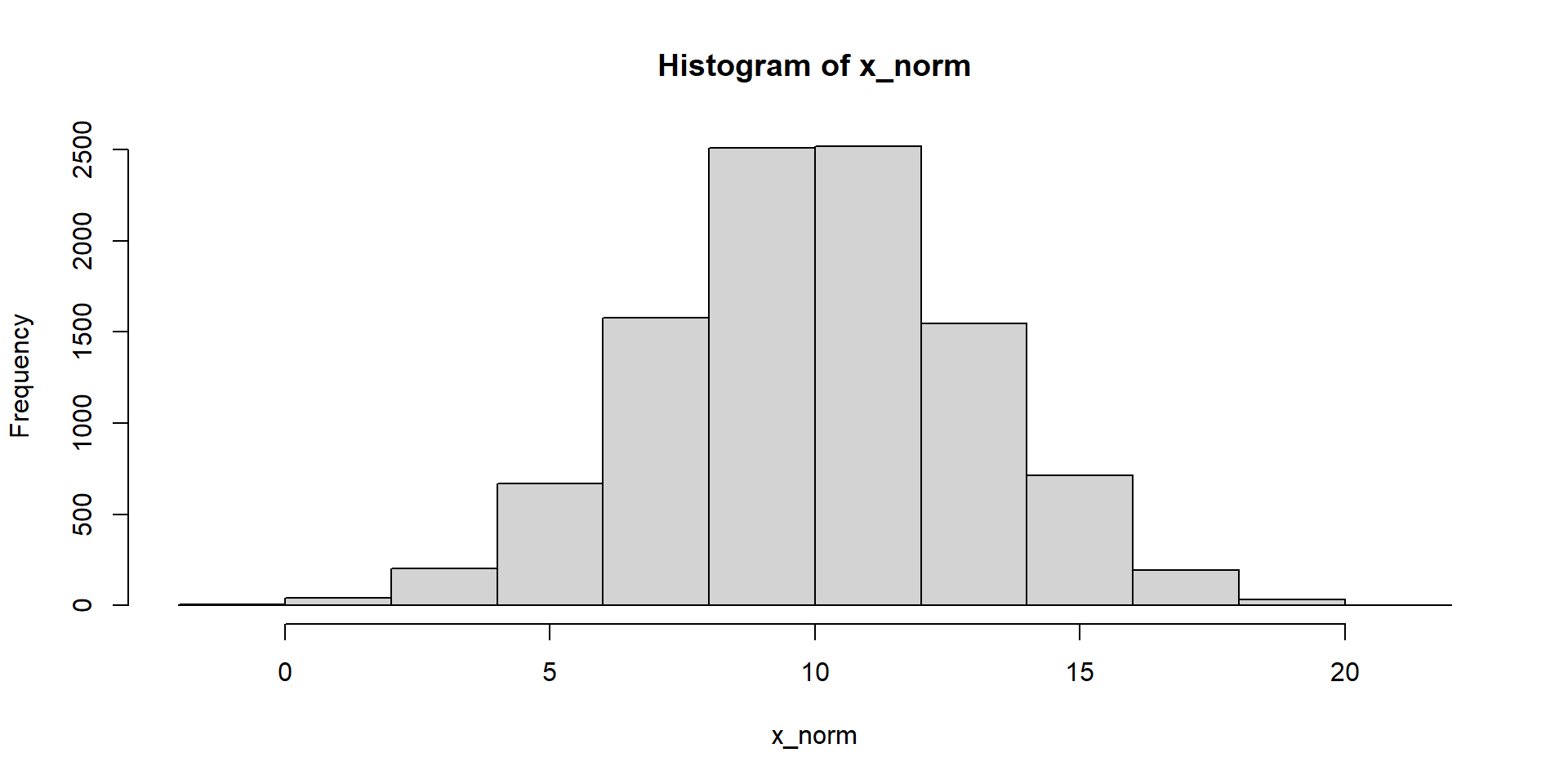
set.seed(12345)
x_norm <- rnorm(10^4, mean = 10 , sd = 3)
head(x_norm) # head = zaciatok vektora, analogicky tail = koniec[1] 11.756586 12.128398 9.672090 8.639508 11.817662 4.546132Metódy riešenia úloh z pravdepodobnosti a štatistiky
Už sme videli generovanie náhodných čísel:
set.seed(12345)
x_norm <- rnorm(10^4, mean = 10 , sd = 3)
head(x_norm) # head = zaciatok vektora, analogicky tail = koniec[1] 11.756586 12.128398 9.672090 8.639508 11.817662 4.546132dnorm - hustota (density)
curve(dnorm, from = -5, to = 5) # jeden zo sposobov kreslenia grafov
curve(dnorm(x, mean = 0.5, sd = 1.5), from = -5, to = 5, col = "red", add = TRUE) 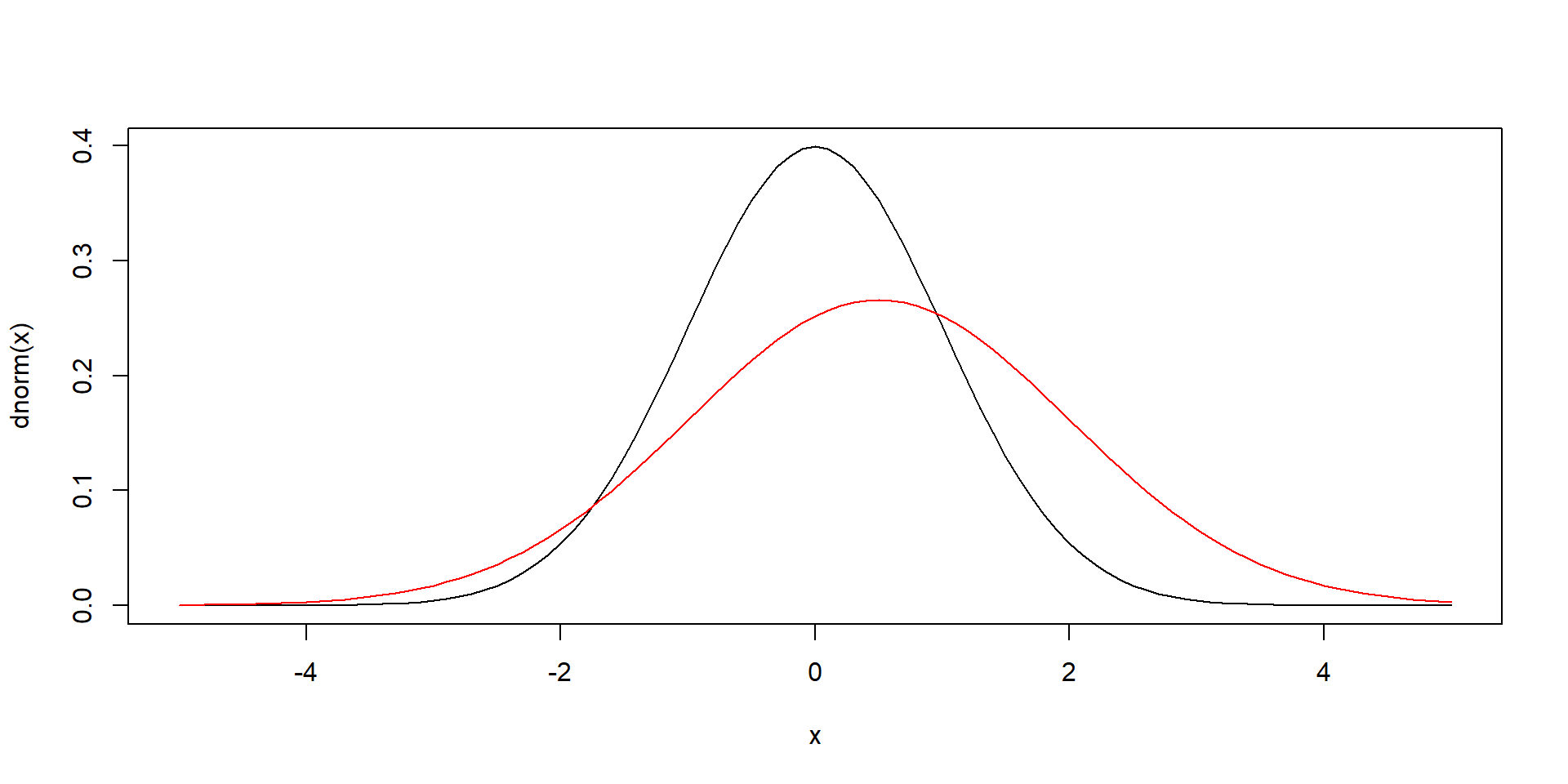
pnorm - distribučná funkcia (probability distribution function)
curve(pnorm, from = -5, to = 5) # jeden zo sposobov kreslenia grafov
curve(pnorm(x, mean = 0.5, sd = 1.5), from = -5, to = 5, col = "red", add = TRUE) 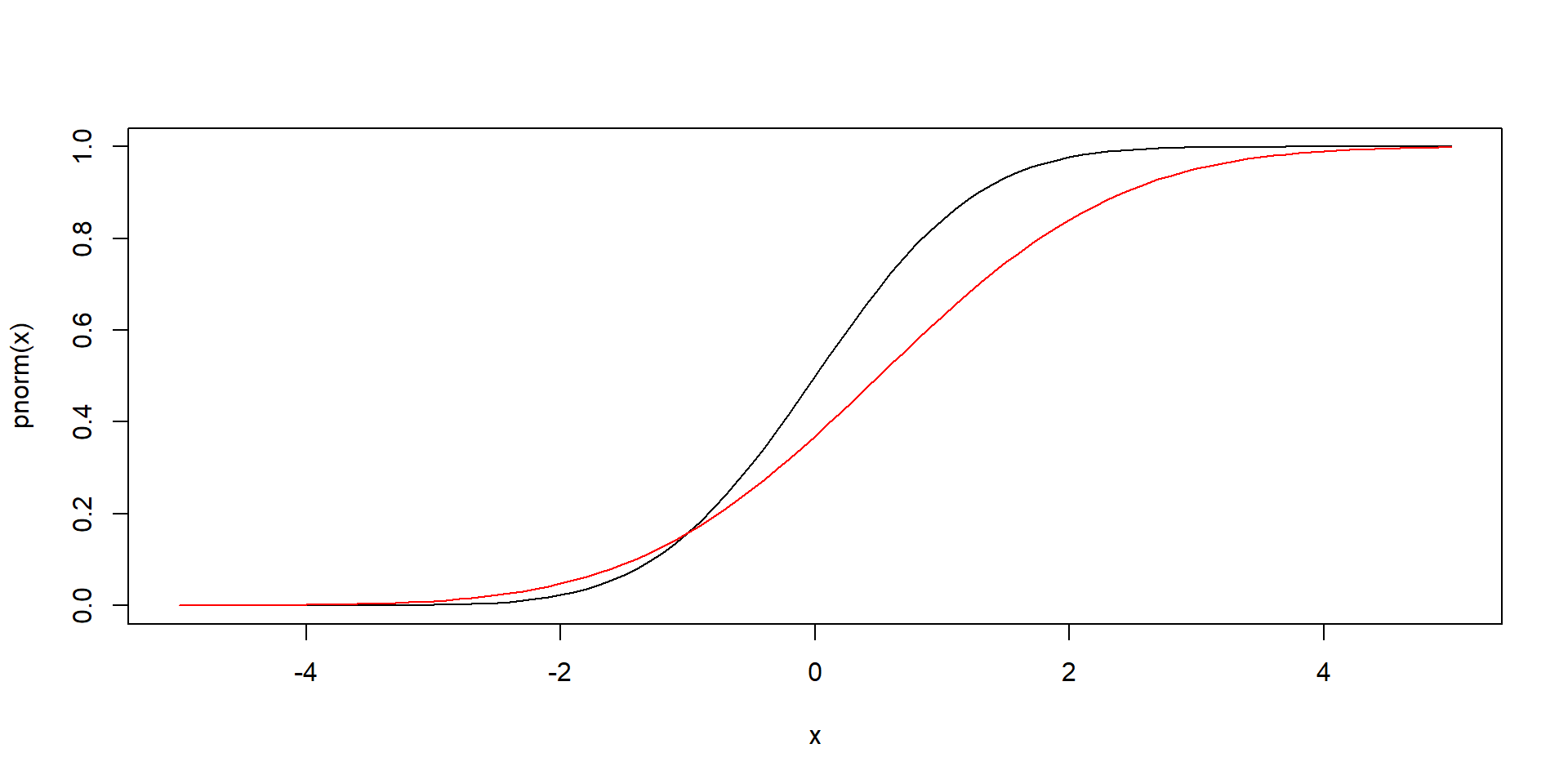
Kontrolná otázka: Čomu sa rovná nasledovná hodnota?
Príklad 1.
Aká je pravdepodobnosť, že náhodná premenná \(\mathcal{N}(0, 4)\) nadobudne hodnotu z intervalu \((1, 2)\)?
Náhodná premenná \(X\) má normálne rozdelenie s nulovou strednou hodnotou a zadanou disperziou. Nakreslite graf funkcie, ktorej hodnota sa rovná pravdepodobnosti, že takáto náhodná premenná nadobudne hodnotu z intervalu \((1, 2)\).Nezávislou premennou je disperzia náhodnej premennej \(X\).
Základná myšlienka: Rozdelenie súčtu nezávislých náhodných premenných s rovnakým rozdelením - s konečnou strednou hodnotou a disperziou - sa pri veľkom počte sčítancov podobná na normálne rozdelenie
Ukážka:
sucet_exp_simulacia <- function(str_hod, pocet_scitancov, pocet_simulacii)
replicate(pocet_simulacii, sum(rexp(pocet_scitancov, rate = 1/str_hod)))
hist(sucet_exp_simulacia(str_hod = 1, pocet_scitancov = 3, pocet_simulacii = 1000)) # X_1 + X_2 + X_3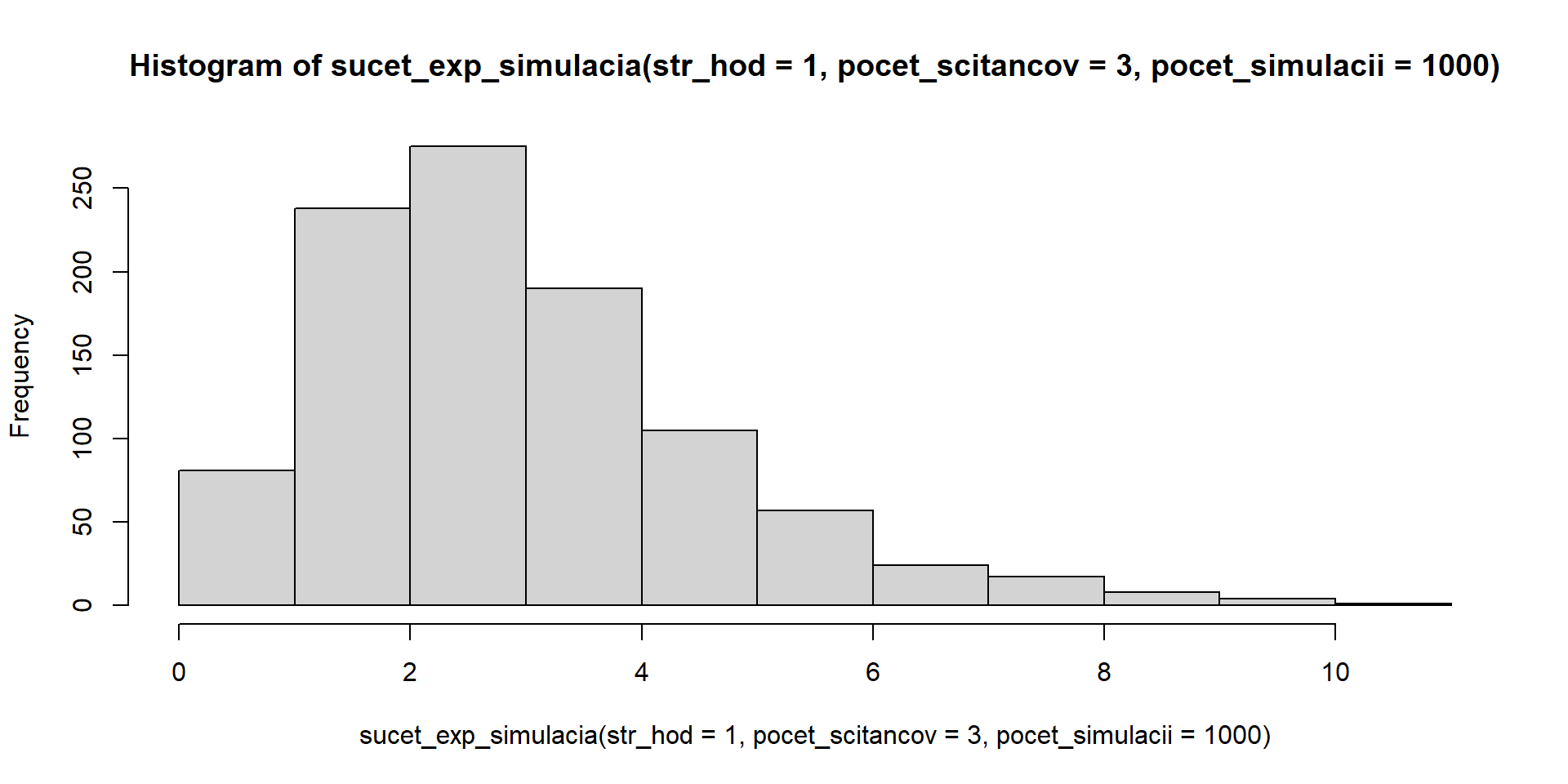
hist(sucet_exp_simulacia(str_hod = 1, pocet_scitancov = 100, pocet_simulacii = 1000)) # X_1 + ... + X_100
Príklad 3. Poistné plnenia pre určité zdravotné poistenie sú nezávislé s exponenciálnym rozdelením so strednou hodnotou 1000. Výška poistného je o 100 vyššia ako očakávaná hodnota poistného plnenia. Uzavretých bolo 100 poistení. Aká je pravdepodobnosť, že výdavky poisťovne budú vyššie ako príjmy?
Možnosti: (A) 0.001 (B) 0.159 (C) 0.333 (D) 0.407 (E) 0.460
Príklad 4. Vek poistencov sa udáva zaokrúhlený na 5 rokov. Vieme, že rozdiely medzi presným a zaokrúhleným vekom majú rovnomerné rozdelenie na intervale (−2.5, 2.5) a pre jednotlivých poistencov sú nezávislé. Zo 48 náhodne vybraných údajov sa vypočíta priemerný vek. Aká je pravdepodobnosť, že sa od skutočného priemerného veku týchto poistencov líši menej ako o štvrť roka?
Možnosti: (A) 0.14 (B) 0.38 (C) 0.57 (D) 0.77 (E) 0.88
Príklad 5. Polícia prijala 100 policajtiek. Tým, ktoré zostanú v polícii až do dôchodku, mesto vyplatí určitú sumu. Ak budú v čase odchodu do dôchodku vydaté, takú istú sumu dostane aj manžel. Predpokladáme, že je známe:
Zaujíma nás počet výplat dohodnutej sumy (policajtkám a ich manželom). Aká je pravdepodobnosť, že ich nebude viac ako 90?
Možnosti: (A) 0.60 (B) 0.67 (C) 0.75 (D) 0.93 (E) 0.99