Metódy riešenia úloh z pravdepodobnosti a štatistiky
Testovanie zhody dvoch pravdepodobnostných rozdelení
Máme dve sady dát
Predpokladáme, že každá z nich je náhodným výberom z určitého rozdelenia
Chceme testovať hypotézu, že tieto rozdelenia sú rovnaké
Príklad 1 (Bakalárska práca Experimenty a vlastné dáta pri vyučovaní pravdepodobnosti a štatistiky, 2015)
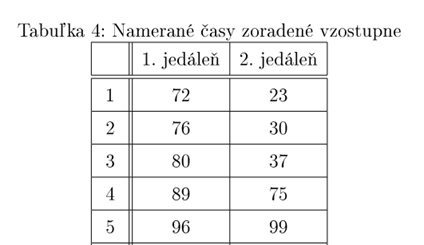
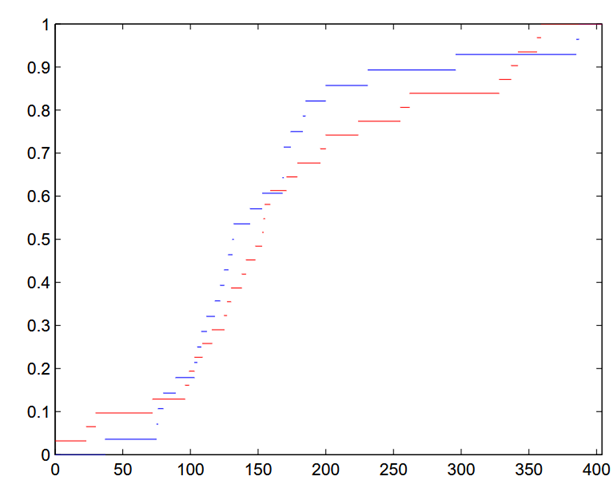
Rozhodli sme sa pozrieť na dĺžku čakania v rade v dvoch študentmi navštevovaných jedálňach v Mlynskej doline, Eat and Meet a Venza. Oslovili sme niekoľko ľudí a požiadali ich, aby si počas jedného týždňa v čase obeda (11:00 - 14:00) merali na stopkách čas od momentu zaradenia sa do radu až po zaplatenie pri kase. V prípade, ak v jedálni rad utvorený nebol, časomiera sa spustila pri uchopení tácky, či prvej súčasti príboru.
Ukážka dát (v sekundách):
Testovacou štatistikou pre Kolomogorovov-Smirnovov test je maximálny rozdiel medzi distribučnými funkciami odhadnutými z dát. Ak je príliš veľký (väčší ako kritická hodnota), tak sa hypotéza zamietne.
V príklade z BP sa hypotéza o zhode rozdelení nezamietla.
Príklad 2 V jednom z cvičení sa generovali náhodné čísla podľa zadaného algoritmu. Dvaja spolužiaci si chcú porovnať svoje riešenie bez toho, aby si posielali kód. Preto sa rozhodnú porovnať rozdelenie získaných hodnôt. Ak sa ich pravdepodobnostné rozdelenie líši, každý program generuje iné rozdelenie, takže aspoň jeden z postupov je nesprávny. Ak sa rozdelenia zhodujú, budú spokojní, lebo nezávisle od seba by rovnakú chybu asi nespravili.
Otestujeme zhodu rozdelení dát vo vektoroch x1 a x2.
Postup v R: funkcia ks.test
Testovanie zhody dát zo zadaným pravdepodobnostným rozdelením
Príklad 3. Jedno z riešení má strednú hodnotu aj disperziu “podozrivo” blízku jednej. Spolu s histogramom nás to vedie k hypotéze, že by mohlo ísť o exponenciálne rozdelenie so strednou hodnotou 1.
Postup v R: znovu funkcia ks.test
Všimnime si, že pri tomto teste majú byť parametre testovaného rozdelenia predne zadané, nie odhadované z dát (metódou maximálnej vierohodnosti a pod.).
Toto je predpoklad testu, týmto testom sa teda nedá testovať napríklad hypotéza, že dáta sú “z nejakého normálneho rozdelenia”.
Na toto slúži napríklad Lillieforsov test, ktorý je úpravou KS testu pre túto situáciu
Existujú aj iné testy an testovanie normality dát (aj iných rozdelení)
Postup v R: funkcia lillie.test z balíka nortest
Príklad 4. Vo vektoroch y1, y2, y3 a y4 sú vygenerované dáta. Otestujte, či pochádzajú z normálneho rozdelenia.
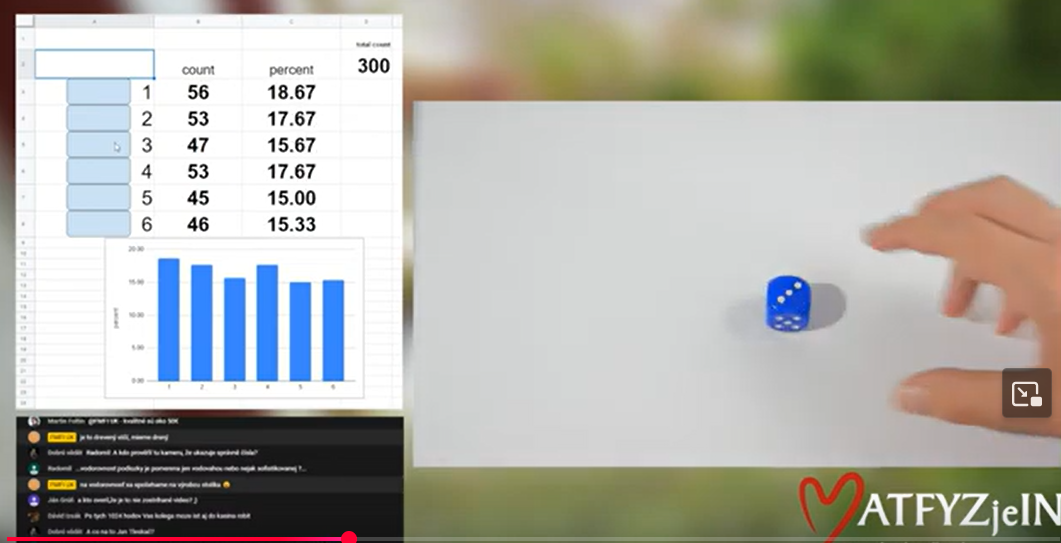
Výsledok jedného hodu je náhodná premenná s hodnotami 1-6, chceme otestovať hypotézu, že pravdepodobnosť každého výsledku je rovnaká.
Použijeme chí kvadrát test dobrej zhody.
Princíp:
Dôležité sú rozdiely medzi relizovanými početnosťami a očakávanými: \[186 - \frac{1024}{6}, 168 - \frac{1024}{6}, \dots\]
Potrebujeme zrušiť efekt znamienok (rovnako postatné sú kladné aj záporné odchýlky) \(\rightarrow\) umocníme ich na druhú \[\left(186 - \frac{1024}{6}\right)^2, \left(168 - \frac{1024}{6}\right)^2, \dots\]
Významnosť rozdielu napr. 10 závisí od toho, aký je očakávaný počet (porovnajme napr. 20 a 2000) vydelíme očakávaným počtom \[\frac{\left(186 - \frac{1024}{6}\right)^2}{\frac{1024}{6}},
\frac{\left(168 - \frac{1024}{6}\right)^2}{ \frac{1024}{6}},
\dots\]
Ak nulová hypotéza platí, ich súčet by mal byť malý. Pre veľký rozdiel nulovú hypotézu zamietame.
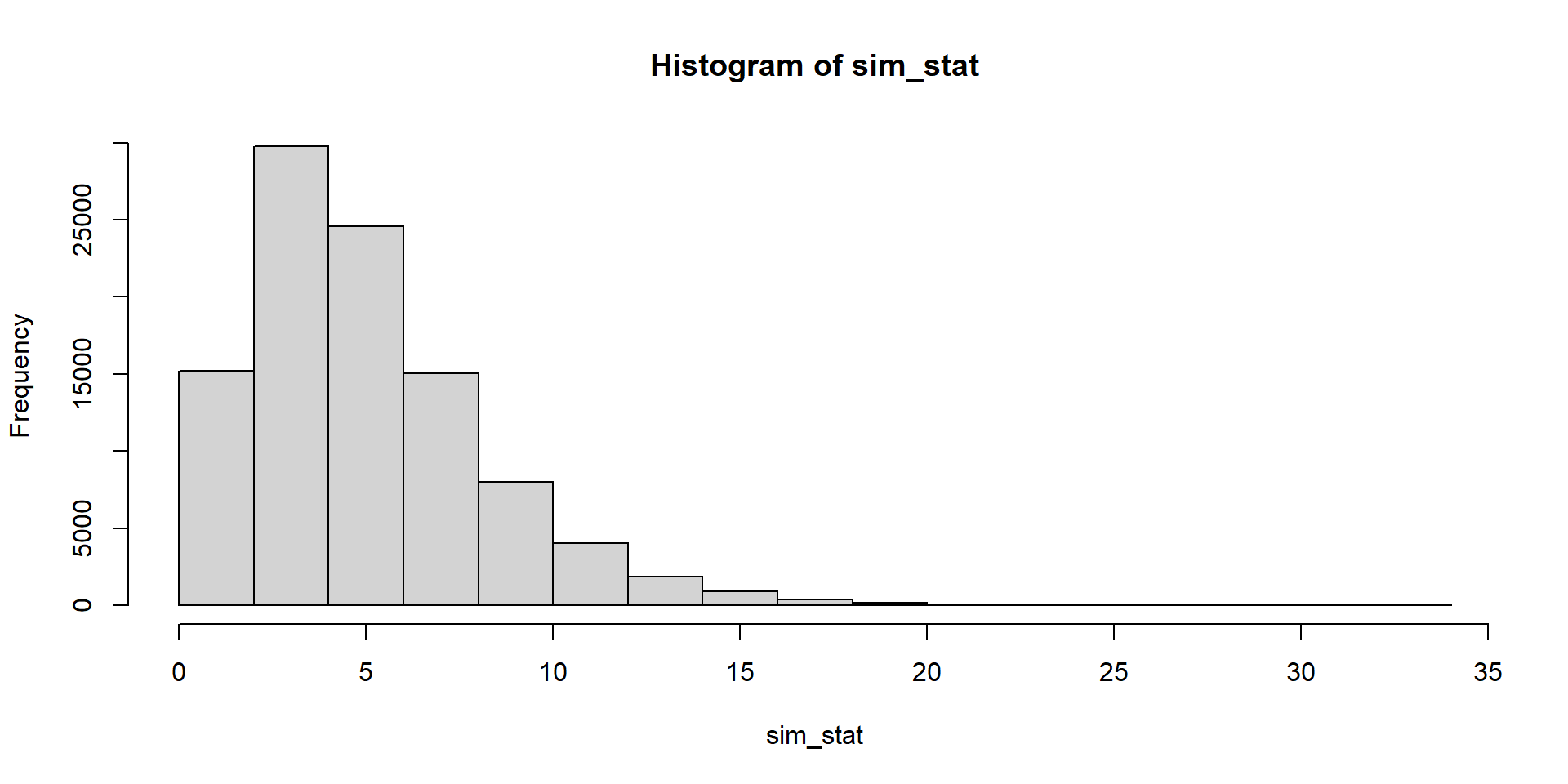
Čo znamená malý/veľký - ukážeme si simuláciami. Budema simulovať výsledky hodnoty štatistiky, ak nulová hypotéza platí:
Vypočítajte hodnotu štatistiky pre hádzanie kockami a rozhodnite, či sa na 5-percentnej hladine významnosti hypotéza zamieta alebo nie.
Z teórie sa vie:
Testovacia štatistika má asymptoticky chí kvadrát rozdelenie, počet stupňov voľnosti je o 1 menší ako počet tried, do ktorých sa triedia dáta
Aproximácia je dobrá, ak je v každej triede očakávaný počet aspoň 5.
qchisq(0.95, df =5)
[1] 11.0705
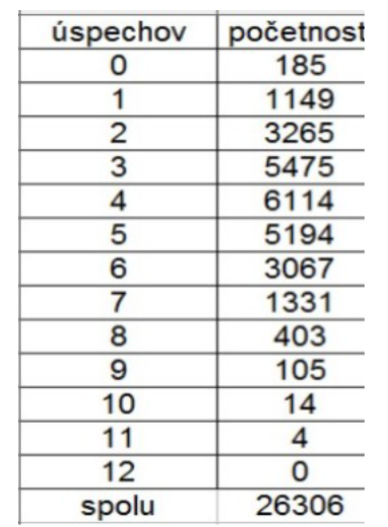
Príklad 6: hádzanie kockou II.
Budeme sa zaoberať výsledkami, ktoré pri hádzaní kockou získal Walter F. L. Weldon (1860 – 1906). Ten tvrdil, že väčším počtom bodiek pri týchto hodnotách je spôsobená jej nepravidelnosť. Táto nepravidelnosť by mohla byť taká výrazná, že hodnoty 5 a 6 nebudú padať rovnako často ako ostatné. Pri svojich pokusoch hádzal dvanástimi kockami. Ako “úspech” označil padnutie päťky alebo šestky a zaznamenával počet úspechov v jednotlivých pokusoch. Tých spravil spolu 26306 s nasledujúcimi výsledkami:
Ak je minca pravidelná, tak počet úspechov v pokuse má binomické rozdelenie. Otestujeme chí kvadrát testom dobrej zhody, že hodnoty v tabuľke pochádzajú z tohto rozdelenia.
Poznámky:
Kvôli požiadavke na minimálny počet očakávaných úspechov bude potrebné zlúčiť niekoľko posledných riadkov.
Pravdepodobnosti binomického rozdelenia v R sa dajú vypočítať funkciou dbinom.
Pre zaujímavosť: Tieto dáta analyzoval aj Peason, podľa ktorého je tento test dobrej zhody pomenovaný.
Generovanie náhodných čísel zo zadaného rozdelenia
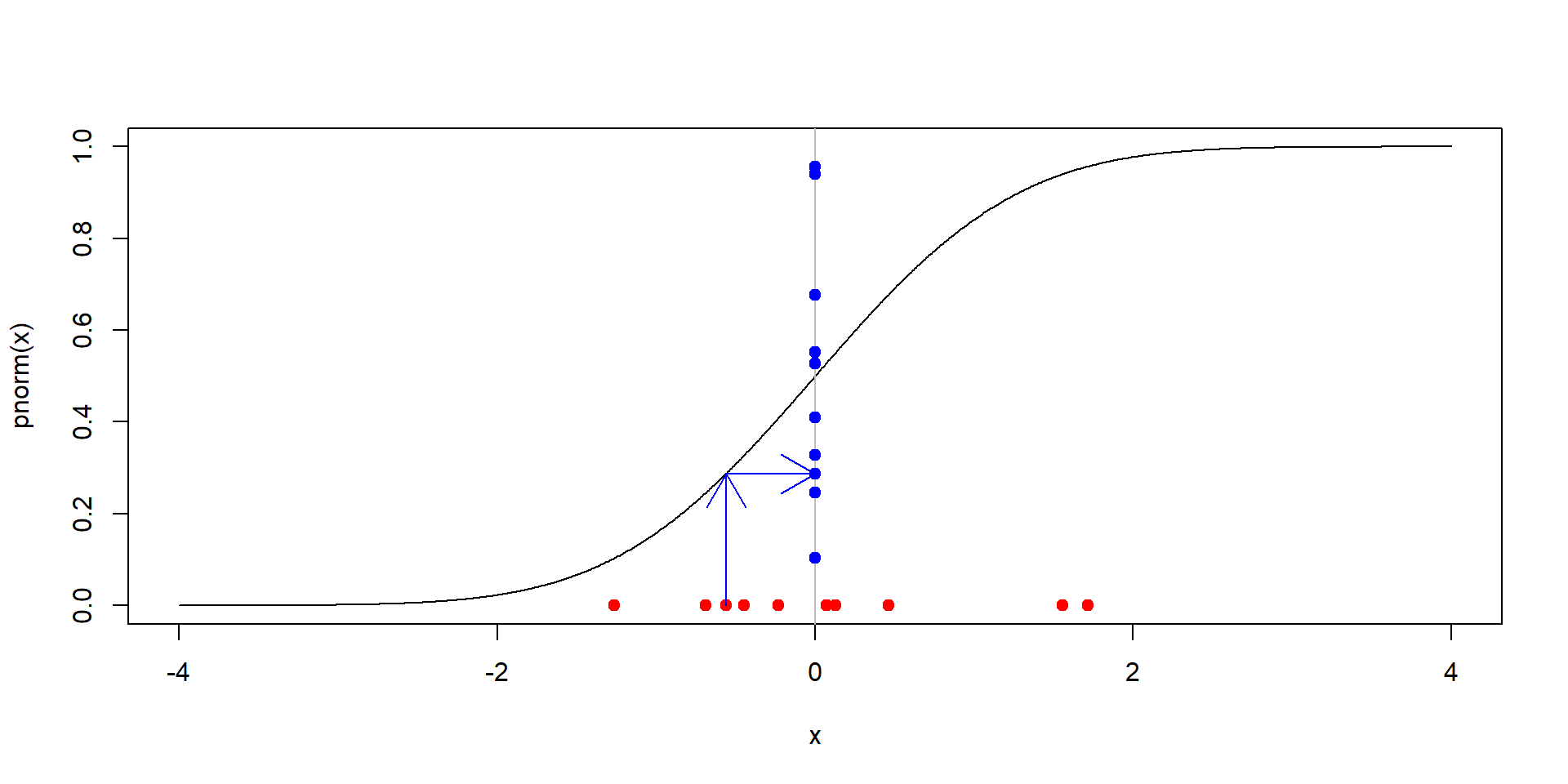
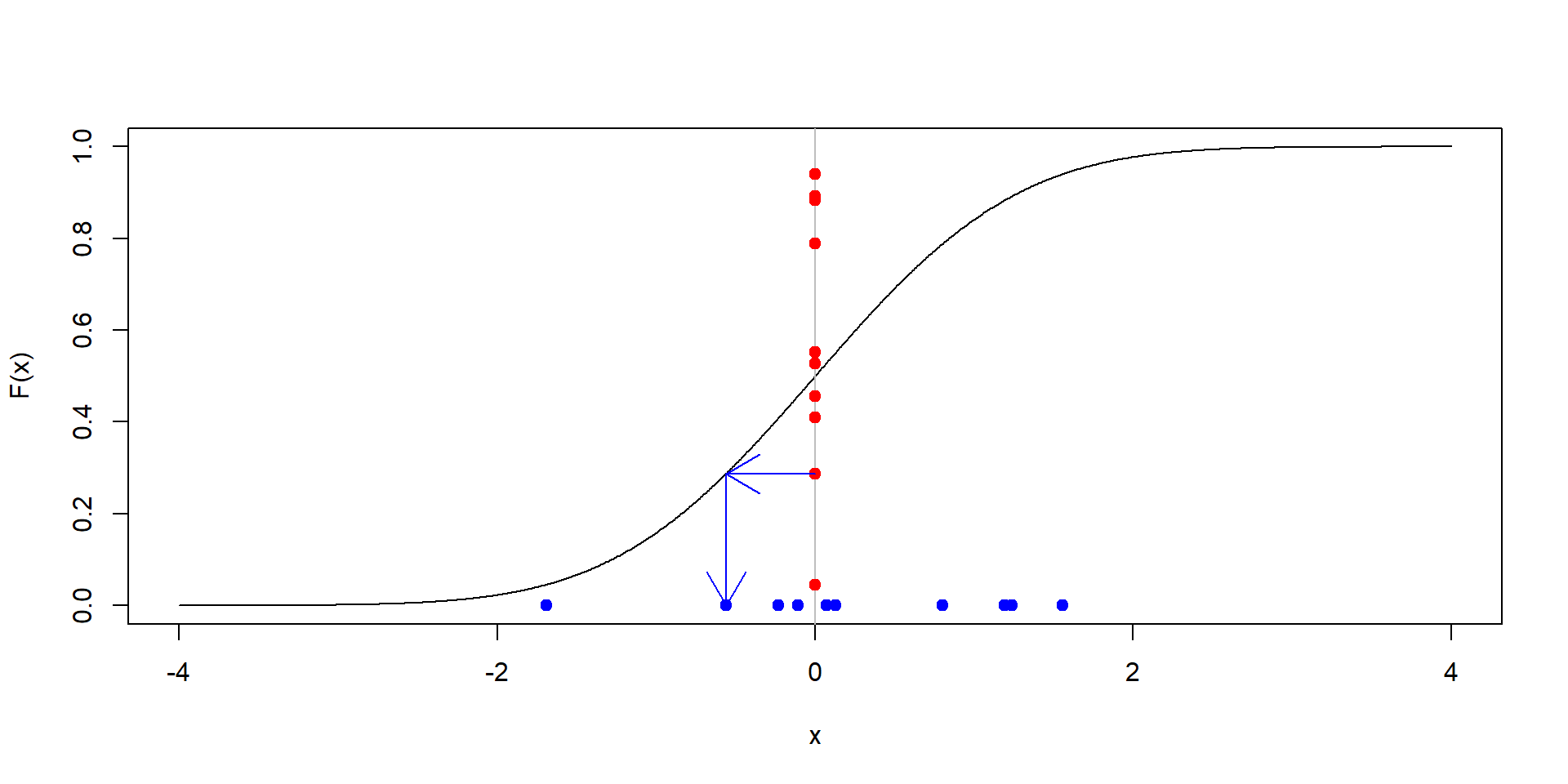
Príklad 5 Aké rozdelenie má náhodná premenná \(F(X)\) kde \(F\) je distribučná premenná \(\mathcal{N}(0,1)\) rozdelenia a \(X\) je náhodná premenná s \(\mathcal{N}(0,1)\) rozdelením?
Teda, čo dostaneme ak budeme dosadzovať náhodné čísla do distribučnej funkcie rozdelenia, z ktorého boli generované? Čo sa zmení, ak namiesto \(\mathcal{N}(0,1)\) zoberieme iné rozdelenie?
Metóda inverznej trasformácie pre generovanie náhodných čísel zo zadaného rozdelenia
Pre spojitú ostro rastúcu distribučnú funkciu:
vygenerujeme náhodné číslo z rovnomerného rozdelenia na intervale \((0,1)\).
dosadíme ho do \(F^{-1}\), teda do inverznej funkcie k distribučnej funkcii nášho rozdelenia
výsledkom je náhodné číslo z rozdelenia daného distribučnou funkcou \(F\)
Na cvičení si ešte ukážeme, čo robiť v prípade,
ak distribučná funkcia nie je monotónna (t.j. na nejakom intervale je konštantná),
ak je distribučná funkcia nespojitá (t.j. má v niektorých bodoch skok),
a teda neexistuje inverzná funkcia definovaná na (0,1).
Príklad 7 Životnosť prístroja je náhodná premenná s hodnotami z intervalu $(0, 40), ktorej hustota je úmerná \((10+x)^{-2}\). Vypočítajte pravdepodobnosť toho, že životnosť je menšia ako 6.
Možnosti zo SOA skúšky:
0.04
0.15
0.47
0.53
0.94
Príklad 8 Životnosť prístroja je náhodná premenná s hodnotami z intervalu $(0, 40), ktorej hustota je úmerná \((10+x)^{-2}\). Vypočítajte pravdepodobnosť toho, že životnosť je menšia ako 6.
Možnosti zo SOA skúšky:
0.04
0.15
0.47
0.53
0.94
Príklad 9 Poisťovňa preplatí škody do výšky 10 (teda ak je škoda vyššia ako 10, vyplatí sumu 10). Výška škody je náhodná premenná s hustotou \(f(x)=2x^{-3}\) pre \(x>1\), inde je \(f(x)=0\). Vypočítajte strednú hodnotu vyplatenej sumy.