[1] 1.720904 1.875773 1.760982 1.886125 1.456481[1] 0.1663718 0.3250954 0.5092243Metódy riešenia úloh z pravdepodobnosti a štatistiky
[1] 1.720904 1.875773 1.760982 1.886125 1.456481[1] 0.1663718 0.3250954 0.5092243Graficky - stĺpcový graf (barplot), nie histogram (lebo máme presné hodnoty, v ktorých chceme zobraziť stĺpce):
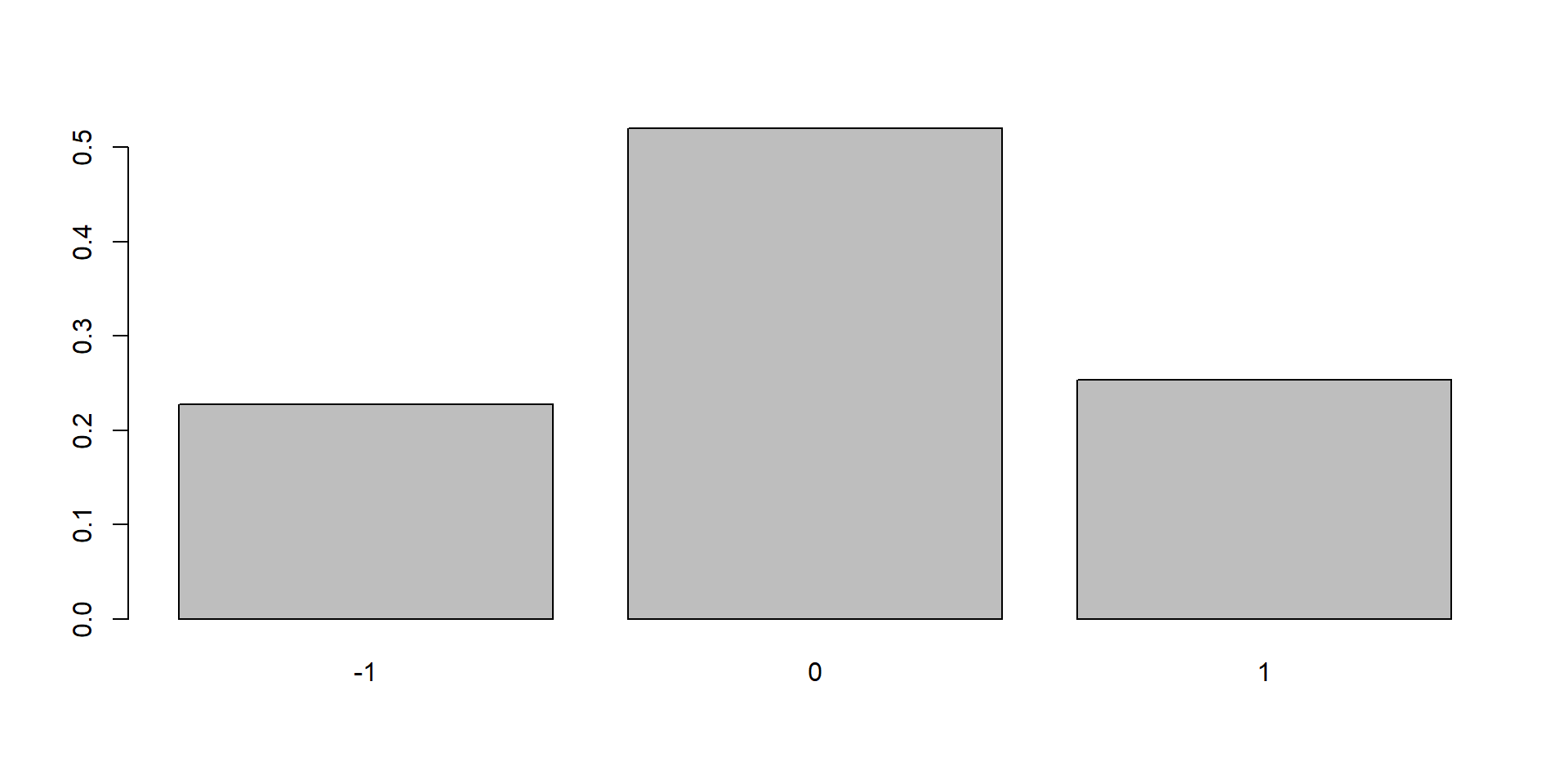
Cvičenie: Aké je presné pravdepodobnostné rozdelenie náhodnej premennej z posledného výpočtu (round(z))?
Romeo a Júlia sa chcú stretnúť. Na miesto stretnutia prídu v náhodnom čase, ktorý si každý z nich nezávisle zvolí rovnomerne náhodne medzi 18:00 a 20:00. Ak prídu na dohodnuté miesto stretnutia a nenájdu tam svojho partnera, budú čakať 15 minút. Aká je pravdepodobnosť, že sa im podarí stretnúť?
Prístup 1 (funkcia pre jednu simuláciu, potom replicate)
priklad1 <- function(){
prichody <- runif(2, min = 0, max = 120) # dva body, nezavisle rovnomerne na (0, 120)
rozdiel <- abs(prichody[1] - prichody[2])
# ALEBO:
# dlzka <- abs(body[2] - body[2])
# ALEBO:
# funkcia `diff` = difference
# dlzka <- abs(diff(body))
return(rozdiel < 15)
}
set.seed(123)
N <- 10^5
simulacie_priklad1 <- replicate(N, priklad1())
prop.table(table(simulacie_priklad1))simulacie_priklad1
FALSE TRUE
0.76628 0.23372 Prístup 2 (generujeme vektory náhodných čísel)
set.seed(123)
N <- 10^5
romeo <- runif(N, min = 0, max = 120) # N prichodov Romea
julia <- runif(N, min = 0, max = 120) # N prichodov Julie
rozdiely <- abs(romeo - julia) # prislusne rozdiely
simulacie_priklad1b <- rozdiely < 15 # vysledok: porovnanie s 15
prop.table(table(simulacie_priklad1b))simulacie_priklad1b
FALSE TRUE
0.76764 0.23236 Grafické znázornenie:
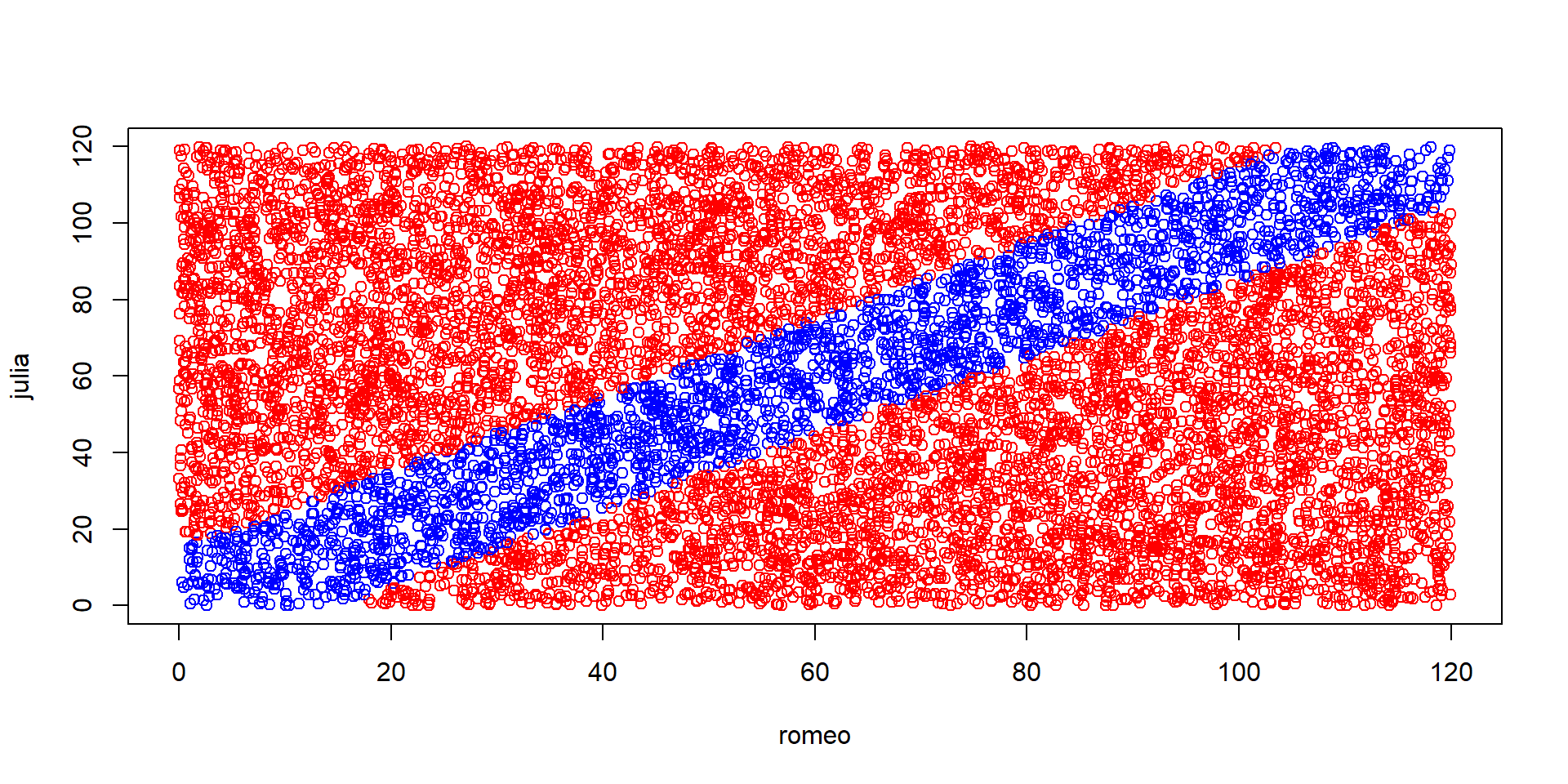
set.seed(123)
N <- 10^4 # zmensime pre lepsie kreslenie
romeo <- runif(N, min = 0, max = 120) # N prichodov Romea
julia <- runif(N, min = 0, max = 120) # N prichodov Julie
rozdiely <- abs(romeo - julia) # prislusne rozdiely
farba <- ifelse(rozdiely < 15, "blue", "red") # uzitocna funkcia `ifelse`
plot(romeo, julia, col = farba)Úpravy pre vylepšenie grafu:
asp = 1 - aby sa mali osi rovnakú mierupch = 20 - body ako plné krúžkylegend, napr.ggplot2set.seed(123)
N <- 10^4
romeo <- runif(N, min = 0, max = 120)
julia <- runif(N, min = 0, max = 120)
# dataframe - stplce mozu mat rozny typ (cislo, retazec, logicka hodnota, ...)
df <- data.frame(romeo = romeo,
julia = julia,
rozdiely = abs(romeo - julia)
)
df$stretnutie <- df$rozdiely < 15
head(df) # head = zaciatok romeo julia rozdiely stretnutie
1 34.50930 37.27100 2.761701 TRUE
2 94.59662 38.94241 55.654209 FALSE
3 49.07723 104.43050 55.353271 FALSE
4 105.96209 39.44085 66.521235 FALSE
5 112.85607 15.08415 97.771926 FALSE
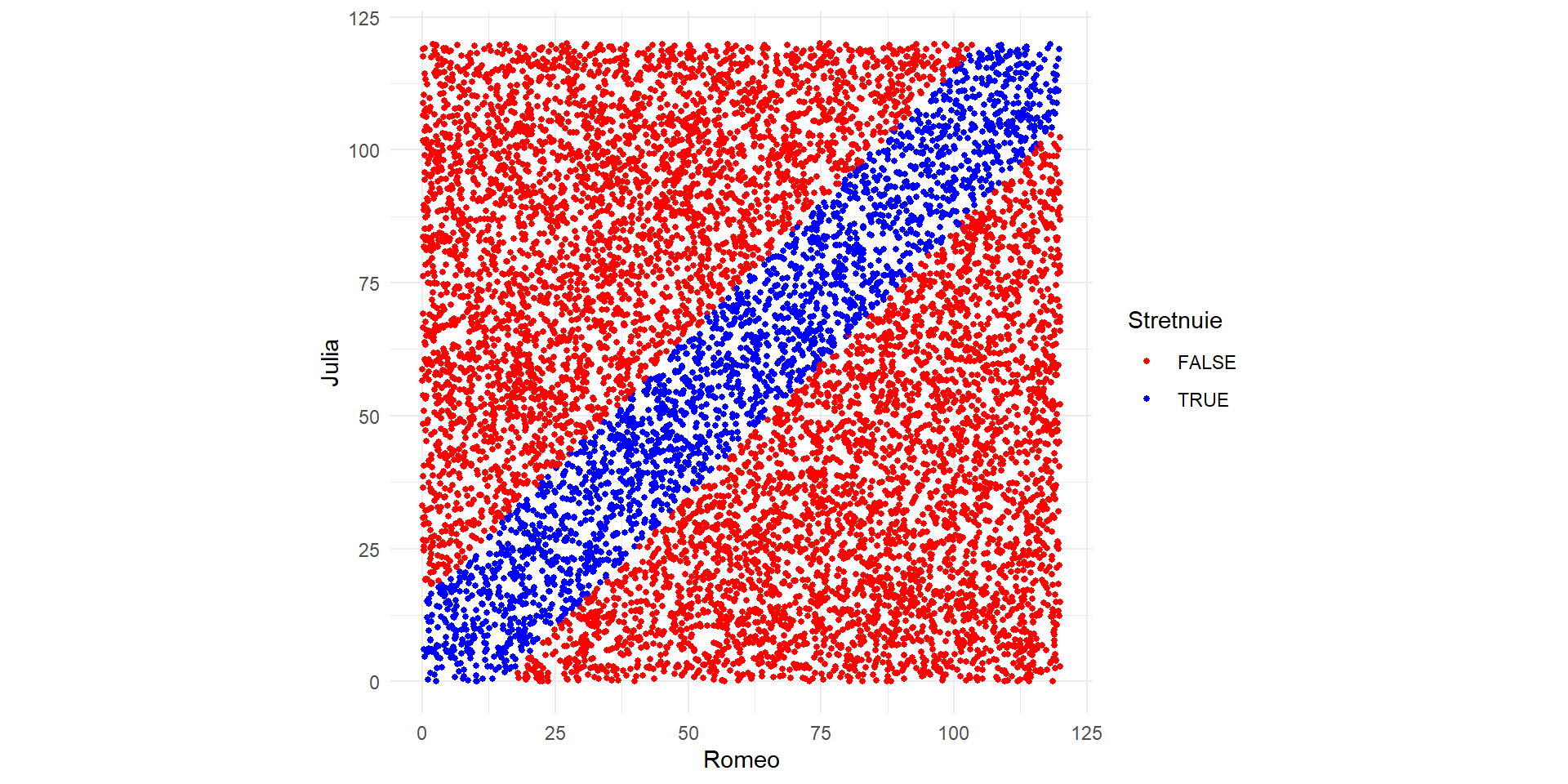
6 5.46678 42.74657 37.279792 FALSElibrary(ggplot2)
ggplot(df, aes(x = romeo, y = julia, color = stretnutie)) +
geom_point(size = 1) + # geom_point - bodovy graf + nastavime velkost bodov
scale_color_manual( # nastavenie farieb
values = c("TRUE" = "blue", "FALSE" = "red"),
name = "Stretnuie"
) +
labs(x = "Romeo", y = "Julia") + # popis osi
theme_minimal() + # bez siveho podkladu
coord_fixed() # ekvivalent `asp = 1`Videli sme:
runif: r je skratka random unif je skratka uniformAnalogicky náhodné čísla z iných rozdelení:
rnorm z normálneho rozdeleniarexp z exponenciálneho rozdeleniaZadávajú sa parametre:
[1] 10.00581[1] 4.008562