Spojité pravdepodobnostné rozdelenia (1) - cvičenia
Metódy riešenia úloh z pravdepodobnosti a štatistiky
Grafické znázornenie bodov
- Budeme vytvárať data frame (táto štruktúra dát bude ešte veľmi užitočná v štatistike pri práci s dátami)
- Grafy budeme kresliť pomocou základnej funkcie
plotz knižnicebase - Nepovinné: úprava grafov pomocou
ggplot2(ukážka bola na prednáške)
Ukážka vytvorenia data framu:
Potom:
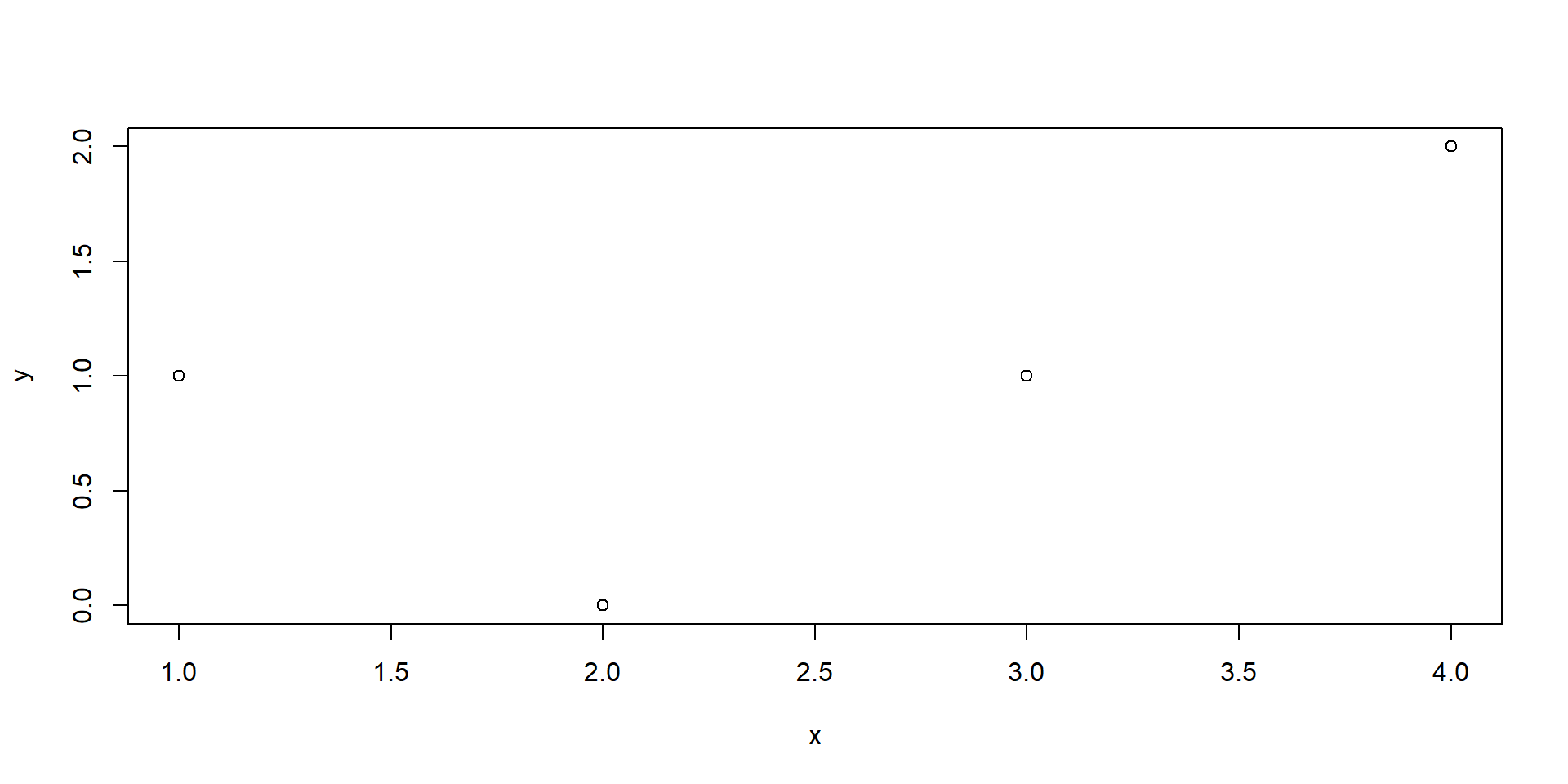
Pristupovanie k stĺpcom:
Využijeme ich na vytvorenie nových:
Môžu byť rôzneho typu:
x y mocnina meno podmienka1
1 1 1 1 A FALSE
2 2 0 4 B FALSE
3 3 1 9 C FALSE
4 4 2 16 D TRUE x y
1 1 1
2 2 0
3 3 1
4 4 2 x y mocnina meno podmienka1
3 3 1 9 C FALSE# ukazka kreslenia grafu
farba <- ifelse(df$podmienka, "blue", "red")
plot(df$x, df$y, pch = 20, col = farba)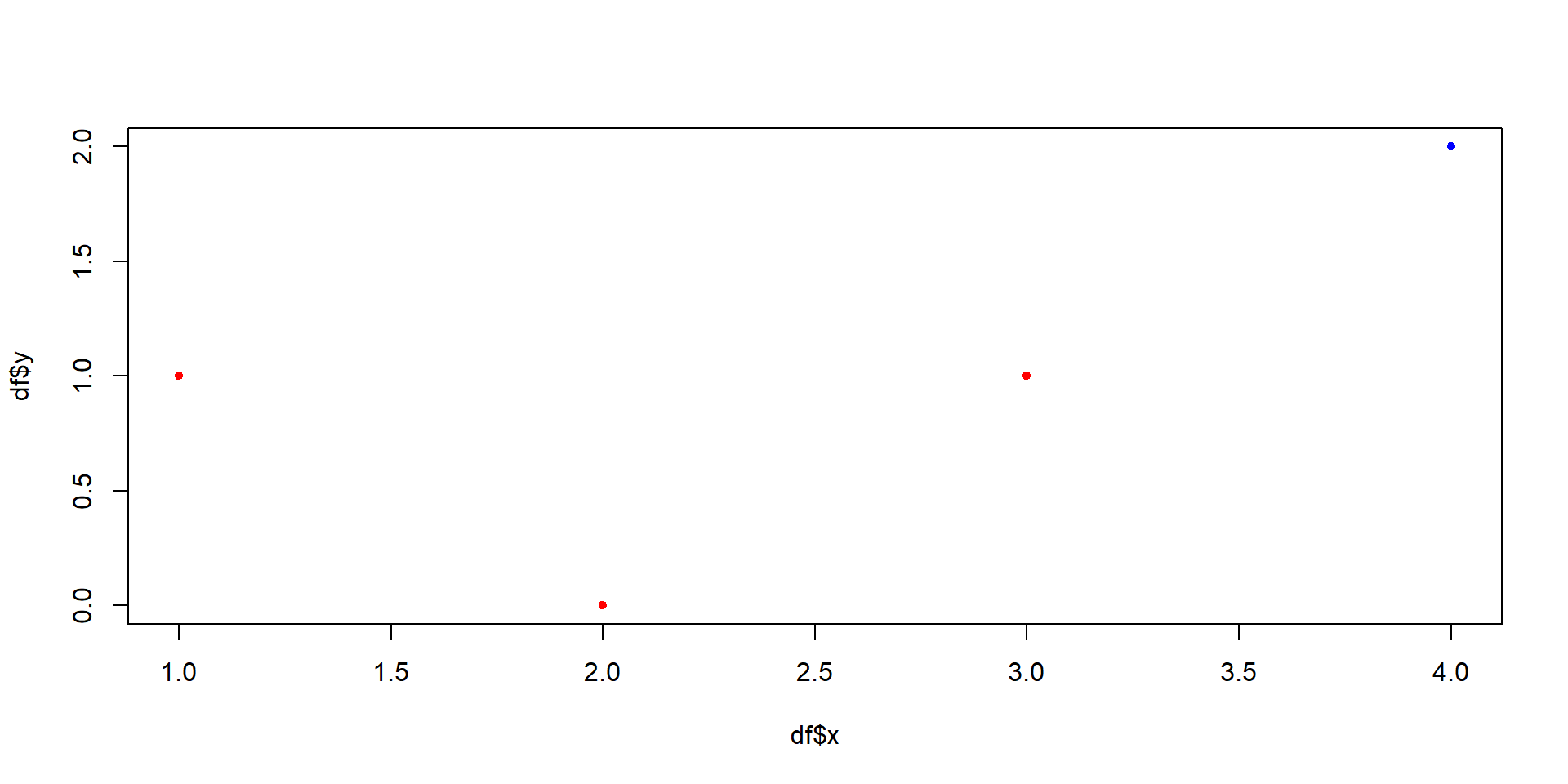
Parameter pch pre plot: https://r-charts.com/base-r/pch-symbols/
Použitie vytvorenej funkcie I:
je_v_kruhu <- function(x, y){
# vystup: TRUE ak je bod vnutri jednotkoveho kruhu, inak FALSE
return(x^2 + y^2 < 1)
}
n <- 5000 # pocet bodov
df <- data.frame(x = runif(n, min = -2, max = 2),
y = runif(n, min = -2, max = 2))
head(df) x y
1 -0.2547249 -0.9547464
2 -1.0129522 -0.7403878
3 0.3043290 -1.0986189
4 1.3097349 1.4320289
5 -1.8872628 0.6717727
6 -1.2989575 -1.6860536 x y vnutri
1 -0.2547249 -0.9547464 TRUE
2 -1.0129522 -0.7403878 FALSE
3 0.3043290 -1.0986189 FALSE
4 1.3097349 1.4320289 FALSE
5 -1.8872628 0.6717727 FALSE
6 -1.2989575 -1.6860536 FALSEGraf:
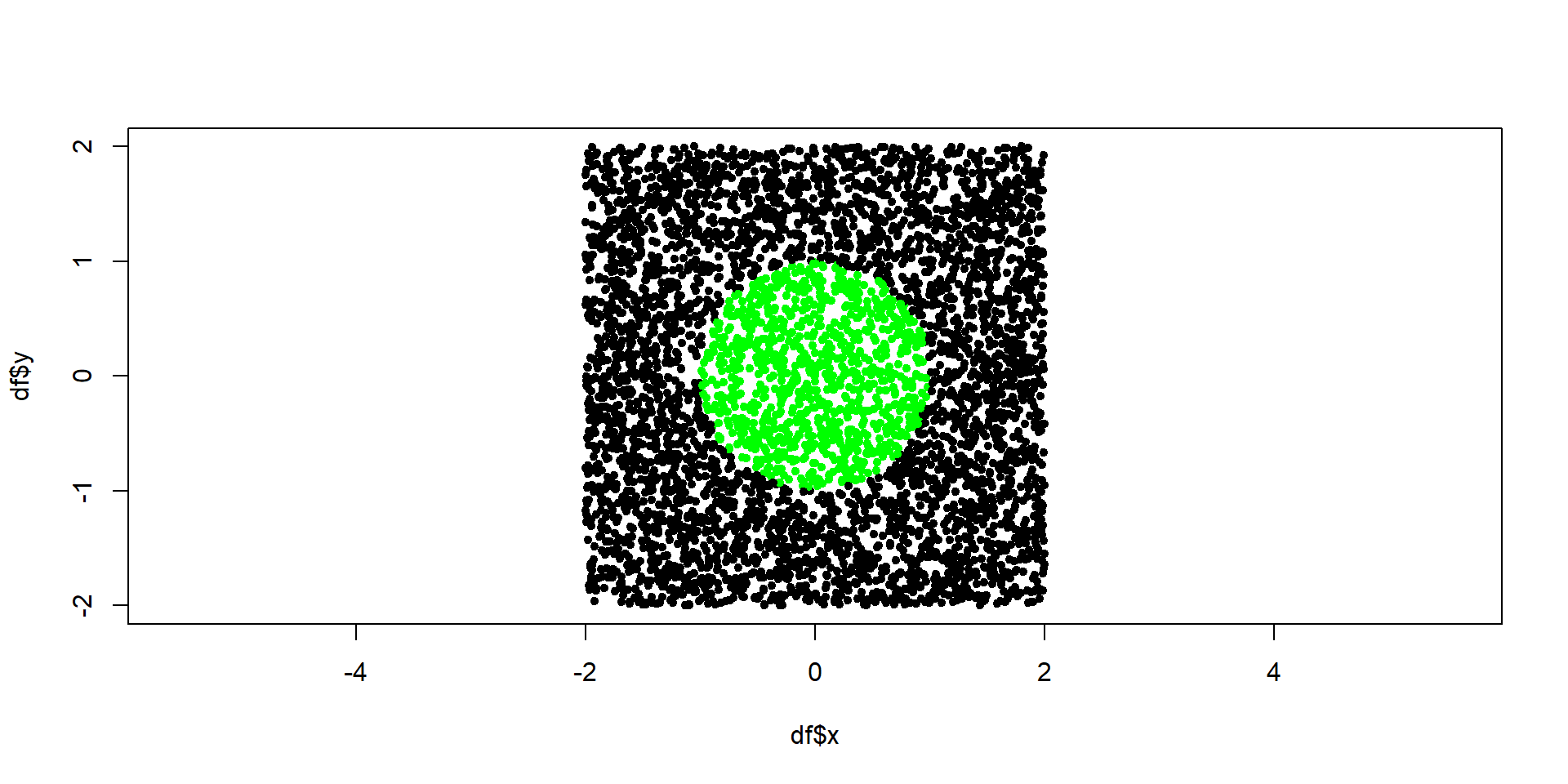
Použitie vytvorenej funkcie II: Podmienka if nevie robiť s vektorovým vstupom, ukážeme si, čo s tým.
set.seed(123)
n <- 5
df <- data.frame(
x = round(runif(n, -1, 1), 1), # pre prehladnost budeme mat zaokruhlene cisla
y = round(runif(n, -1, 1), 1)
)
df x y
1 -0.4 -0.9
2 0.6 0.1
3 -0.2 0.8
4 0.8 0.1
5 0.9 -0.1# Uvazujme nasledovnu funkciu
f <- function(x, y) {
if (x + y > 0) {
return(x + y)
} else {
return(-1)
}
}
# napriklad
f(-0.4, 0.2)[1] -1[1] 0.2Vyskúšajte, že nasledovný kód nefunguje (if, else nevie robiť s vektorovým argumentom):
Riešenie 1: vektorizácia pomocou funkcie Vectorize
x y z1
1 -0.4 -0.9 -1.0
2 0.6 0.1 0.7
3 -0.2 0.8 0.6
4 0.8 0.1 0.9
5 0.9 -0.1 0.8Riešenie 2: Podmienka ifelse s vektorovým argumentom pracovať vie
x y z1 z2
1 -0.4 -0.9 -1.0 -1.0
2 0.6 0.1 0.7 0.7
3 -0.2 0.8 0.6 0.6
4 0.8 0.1 0.9 0.9
5 0.9 -0.1 0.8 0.8Príklad 2 znovu: Na úsečke dĺžky 1 sú náhodne zvolené dva body, ktoré úsečku rozdelia na tri časti. Aká je pravdepodobnosť, že žiadna z tých častí nebude dlhšia ako 3/4?
Graficky znázorníme simulácie a odhadneme pravdepodobnosť:
- vygenerujte data frame so stĺpcami
x,y, v ktorých bude x-ová a y-ová súradnica vygenerovaných bodov - vytvorte stĺpec testujúci podmienku zo zadania
- nakreslite graf a odhadnite pravdepodobnosť
Iné rozdelenia
Z prednášky:
runif: náhodné čísla z rovnomerného rozdeleniarnormz normálneho rozdeleniarexpz exponenciálneho rozdelenia
Existujú aj iné, začínajú písmenom r (random), potom je skratka rozdelenia.
Na prednáške sme robili:
Príklad 7: Životnosť žiarovky má exponenciálne rozdelenie so strednou hodnotou 1 (jednotku času teda uvažujeme takú, že je ňou očakávaná životnosť žiarovky). Kúpili sme 10 žiaroviek a postupne ich vymieňame. Aké je pravdepodobnostné rozdelenie času, počas ktorého nám týchto 10 žiaroviek bude stačiť?
ziarovky <- function(pocet_ziaroviek, ocakavana_zivotnost){
zivotnosti <- rexp(pocet_ziaroviek, rate = 1/ocakavana_zivotnost)
return(sum(zivotnosti))
}
ziarovky_simulacia <- replicate(10^5, ziarovky(10, 1))
hist(ziarovky_simulacia)[1] 9.998098[1] 9.928435
Príklady na samostatné riešenie: odhadovanie rozdelenia zo simulácií
Príklad 10 (písomka 2025): \(X\) a \(Y\) sú nezávislé náhodné premenné s exponenciálnym rozdelením so strednou hodnotou \(\mu\). Nájdite pravdepodobnostné rozdelenie podielu \(\frac{X}{X+Y}\) v závislosti od parametra \(\mu\).
Riešenie:
priklad10 <- function(mi){
x <- rexp(1, rate = 1/mi)
y <- rexp(1, rate = 1/mi)
return(x/(x + y))
}
priklad10_simulacia_hist <- function(mi){
simulacia <- replicate(10^5, priklad10(mi))
hist(simulacia)
}
set.seed(123)
priklad10_simulacia_hist(1)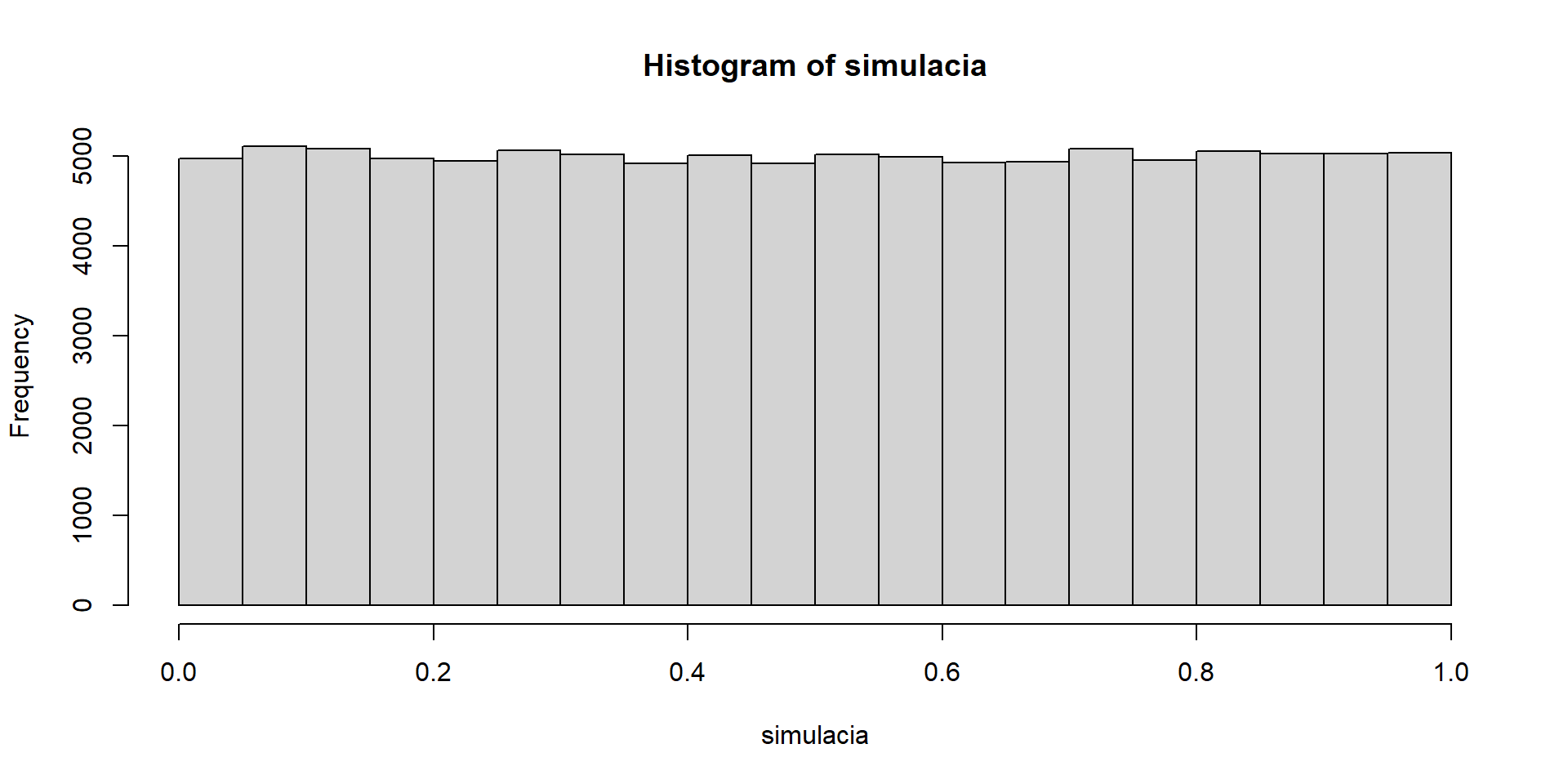
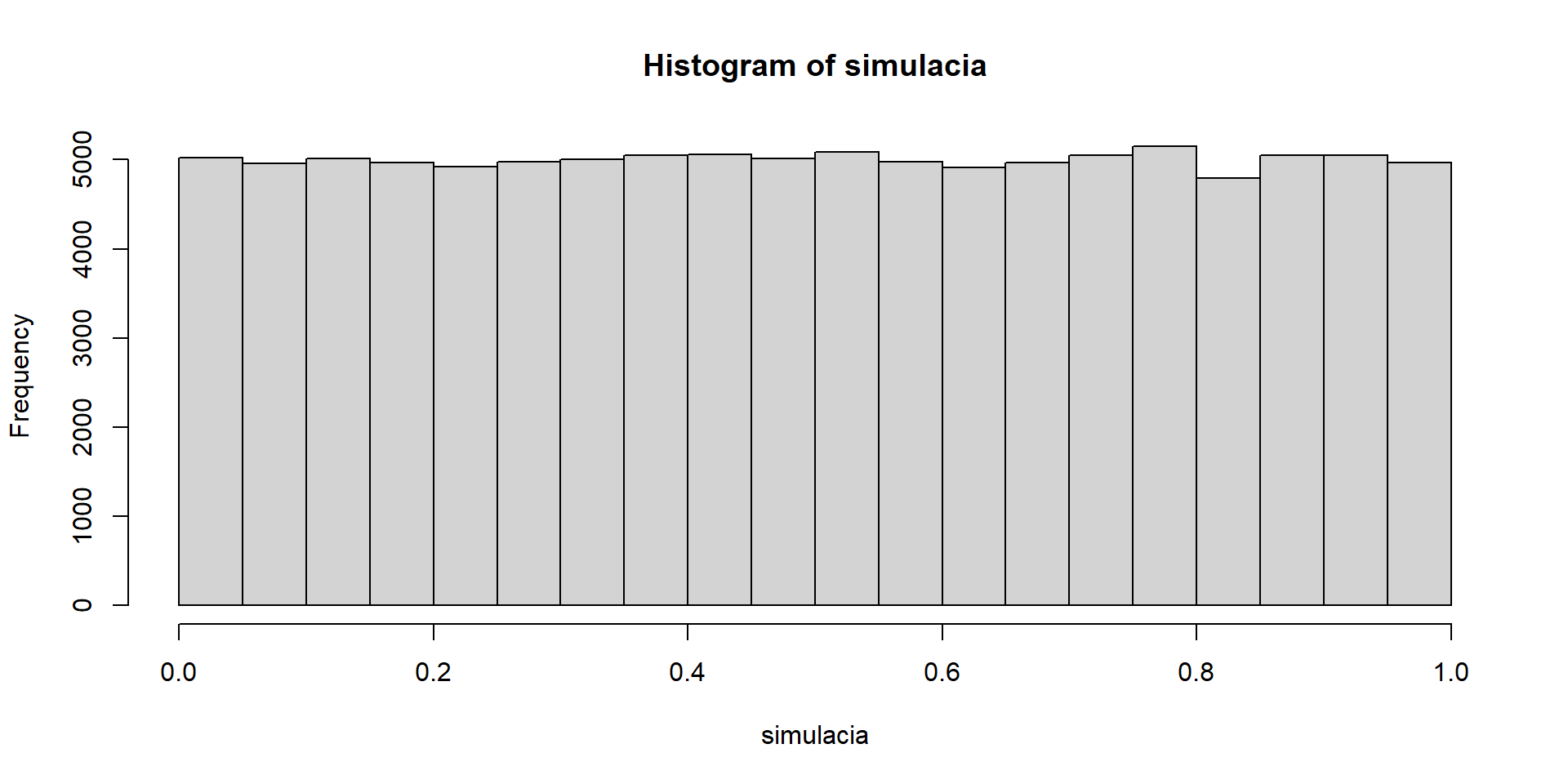
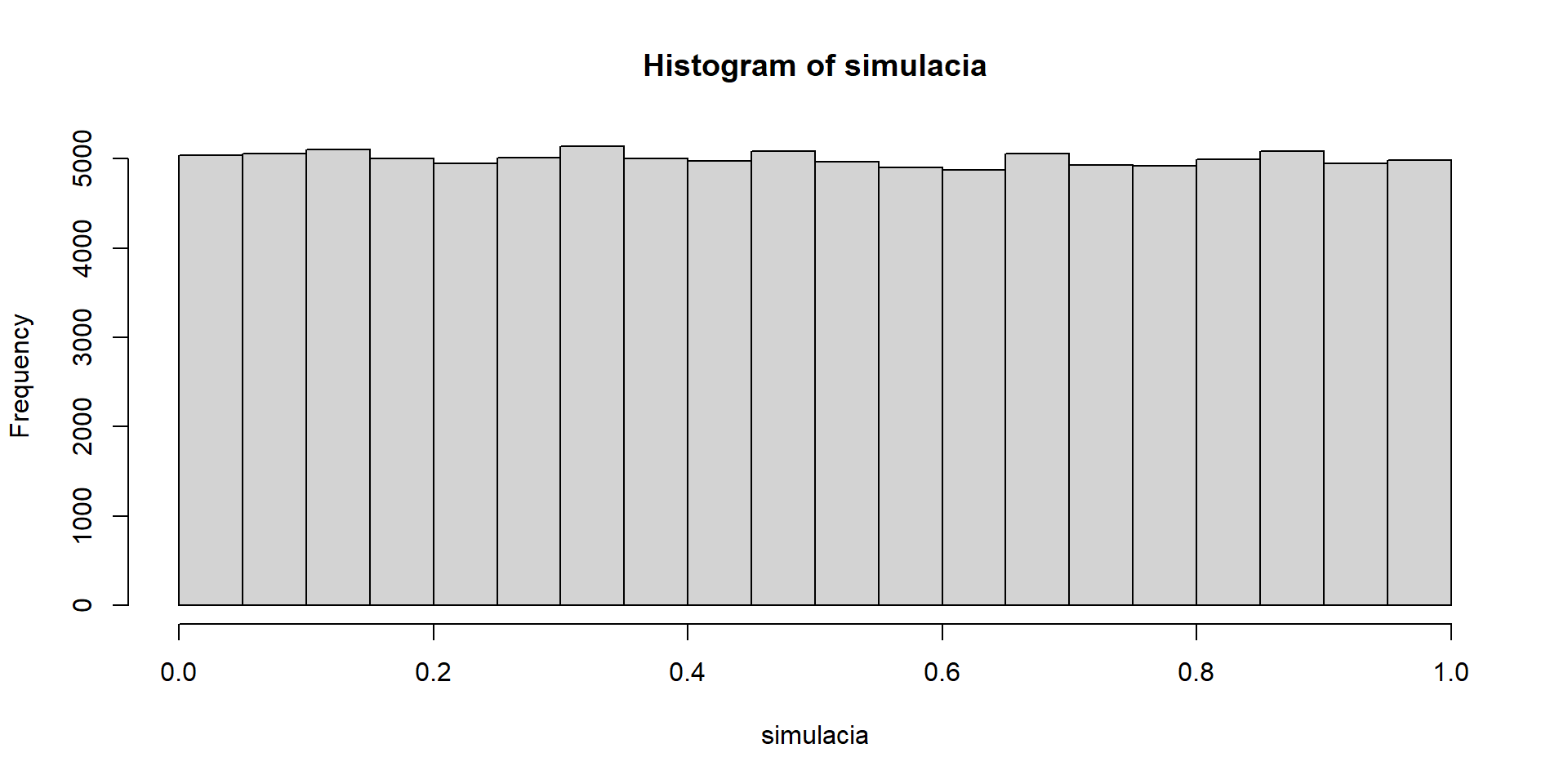
Po vyskúšaní niekoľkých hodnôt prídeme k hypotéze, že by to mohlo byť rovnomerné rozdelenie na intervale \((0, 1)\).
Na samostatné riešenie:
Príklad 11: \(X\) a \(Y\) sú nezávislé náhodné premenné s exponenciálnym rozdelením so strednou hodnotou \(\mu\). Nájdite pravdepodobnostné rozdelenie podielu \(\frac{X-Y}{X+Y}\) v závislosti od parametra \(\mu\).
Príklad 12: \(X\) je náhodná premenná s rovnomerným rozdelením na intervale \((0, 1)\). Nájdite rozdelenie náhodnej premennej \(-\ln(X)\).
Príklad 13: Nájdite rozdelenie náhodnej premennej, ktorá vznikne podľa nasledovného algoritmu: