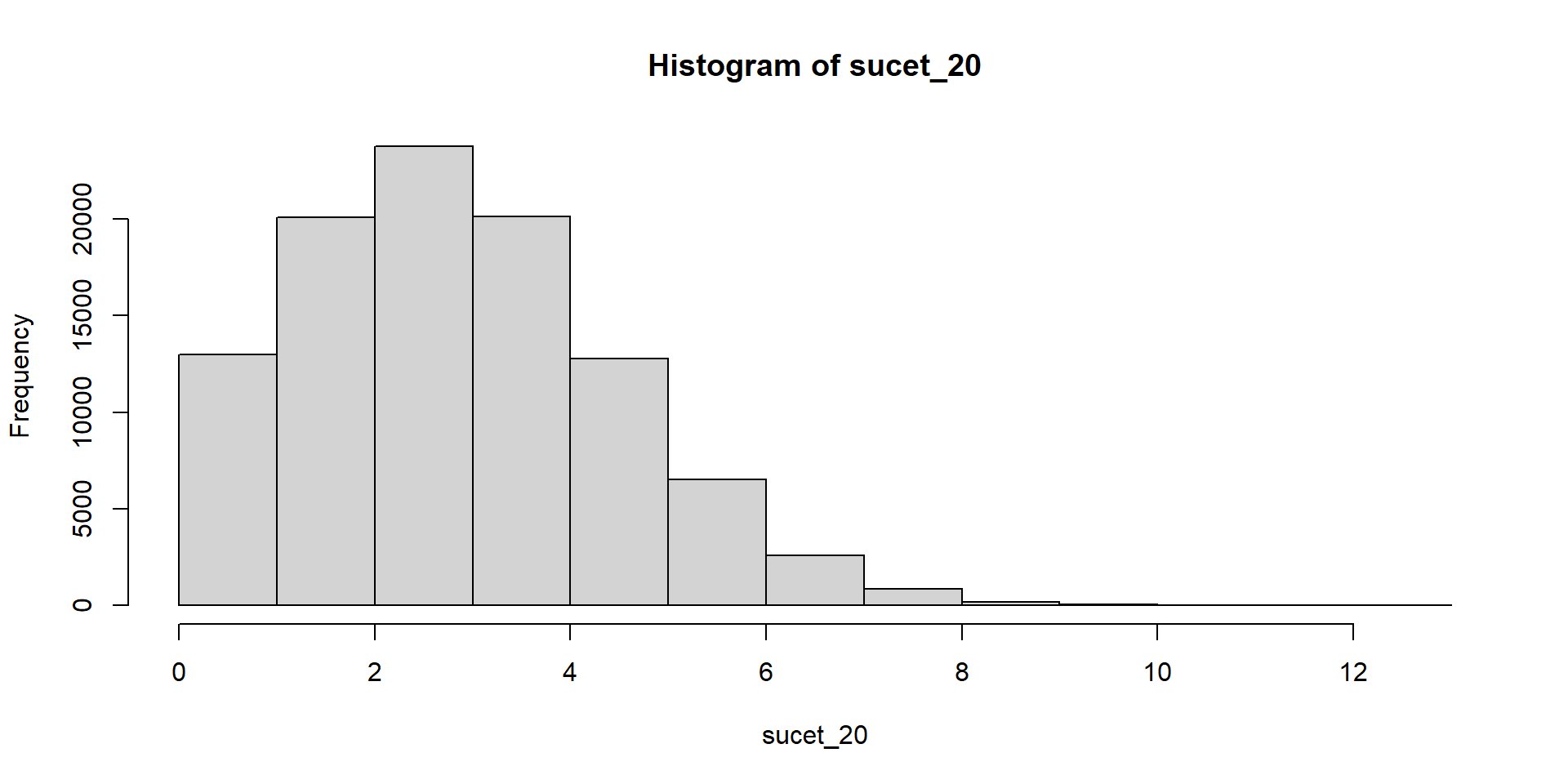
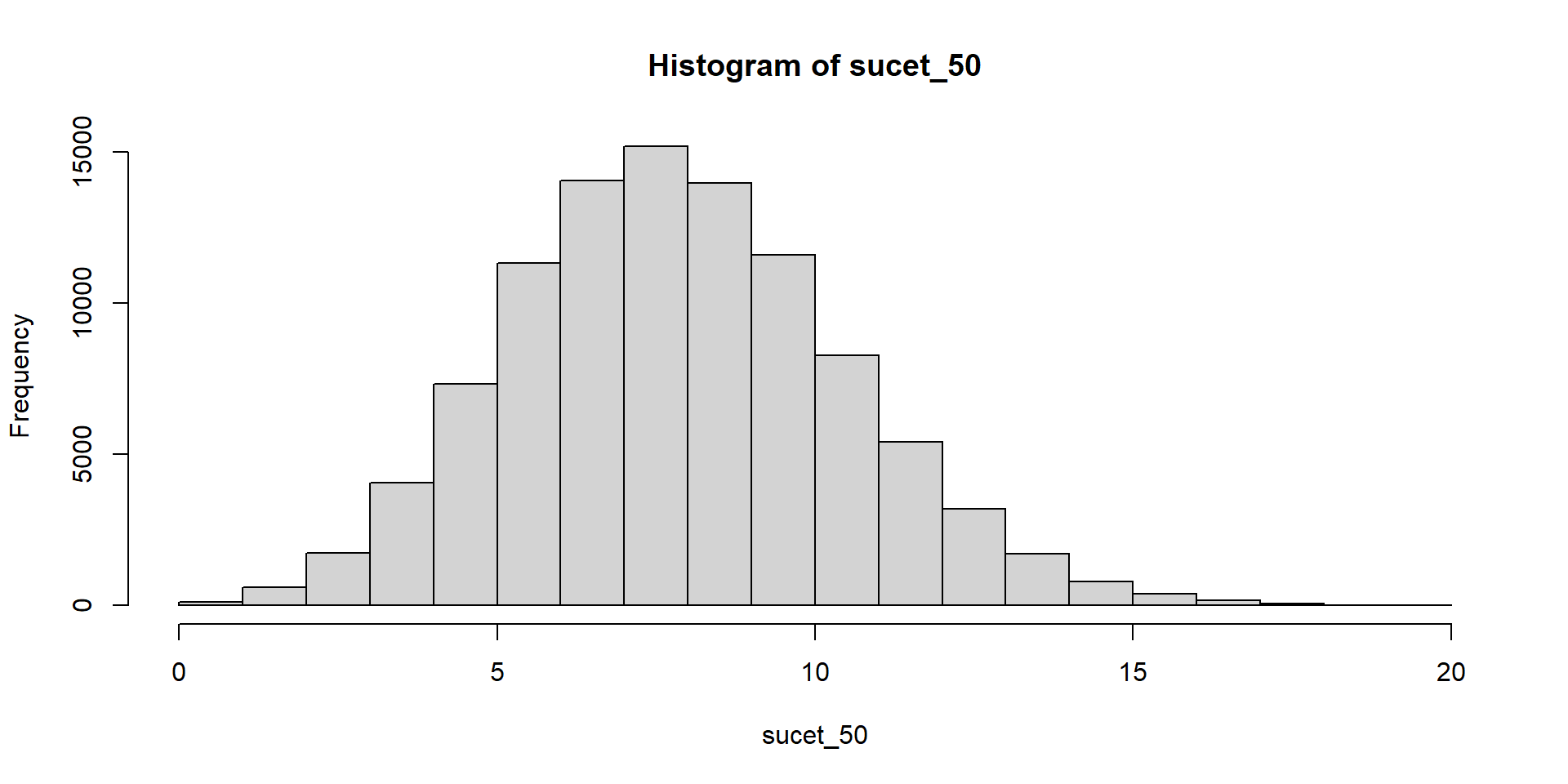
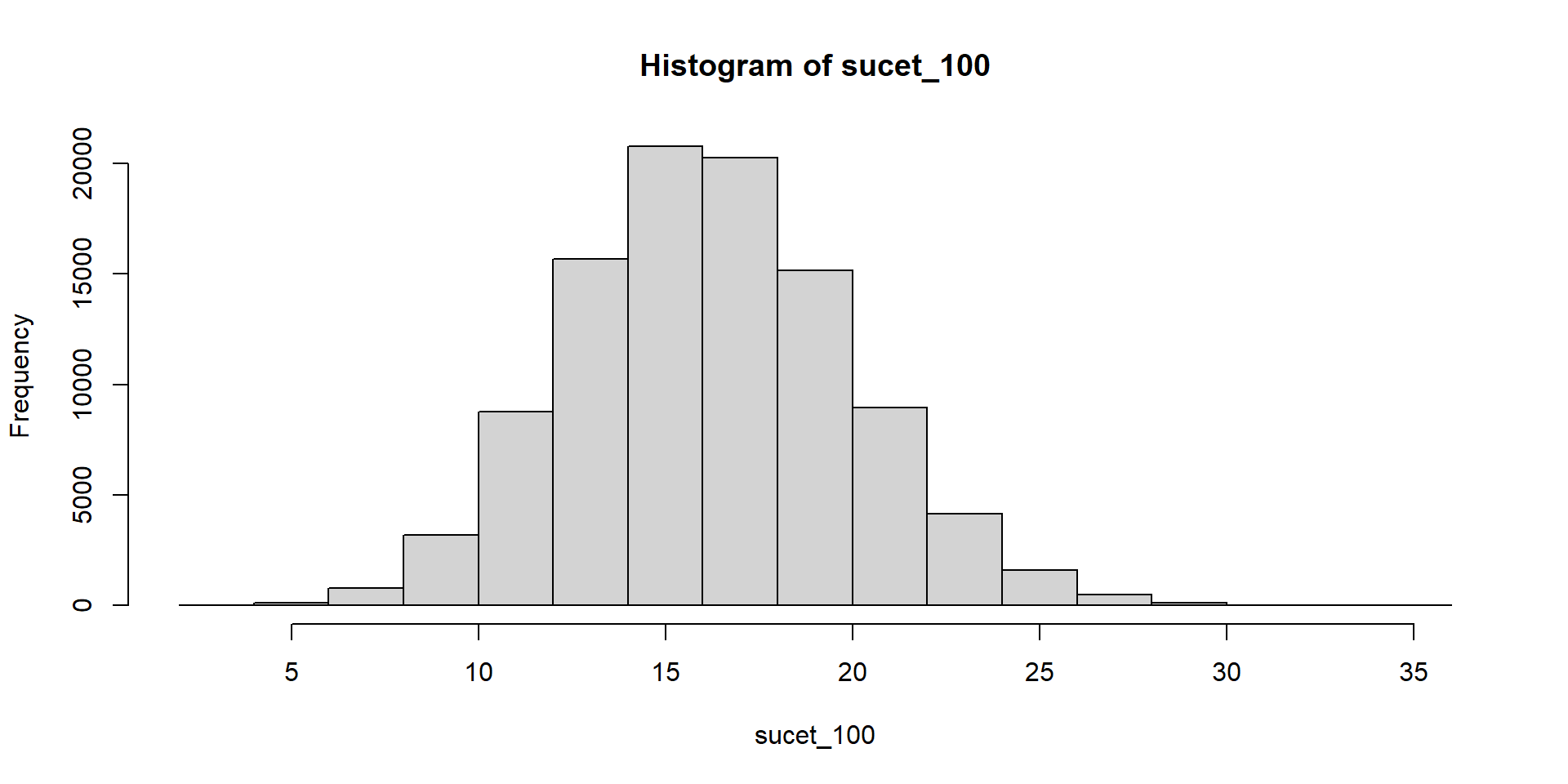
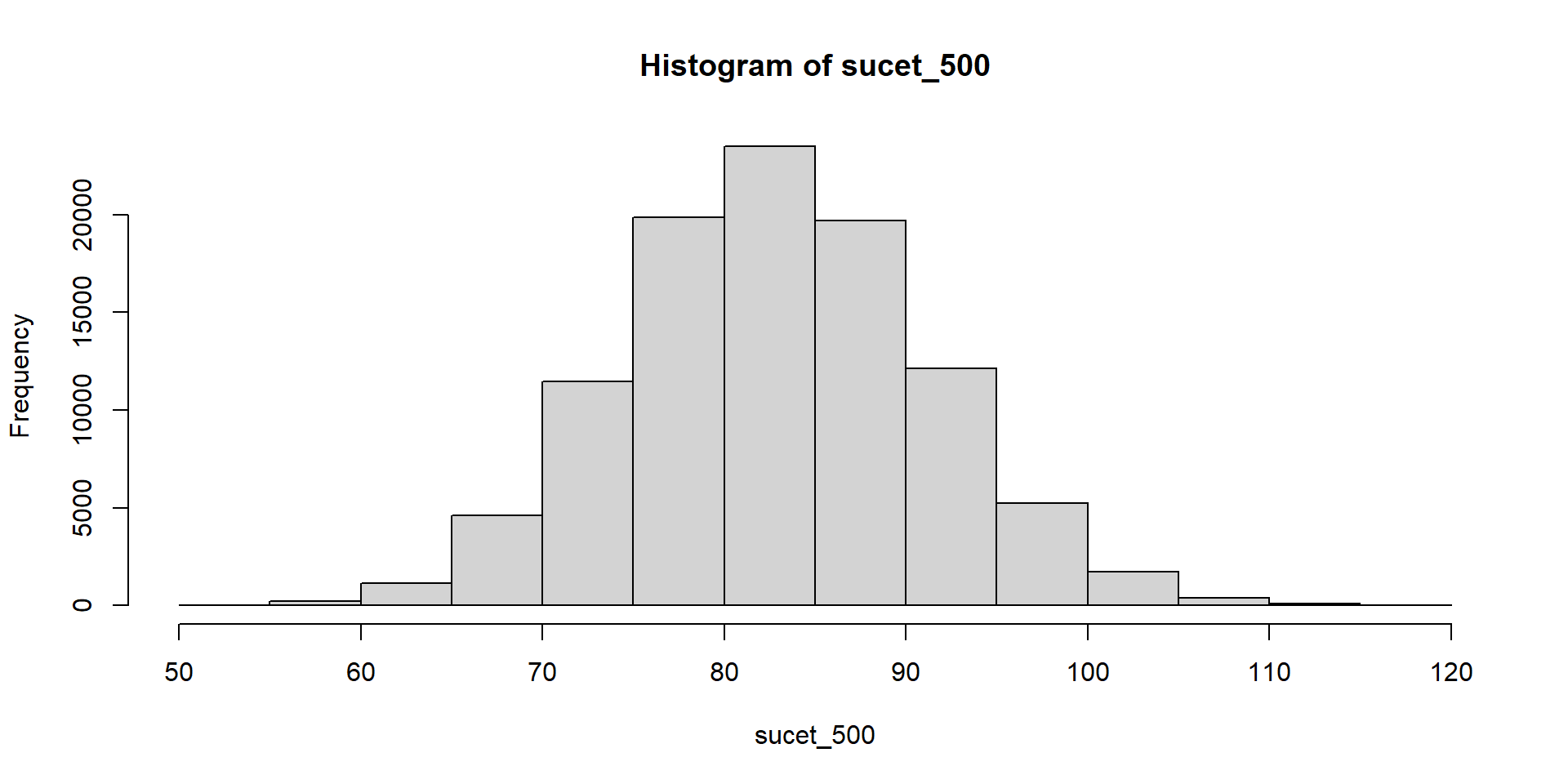
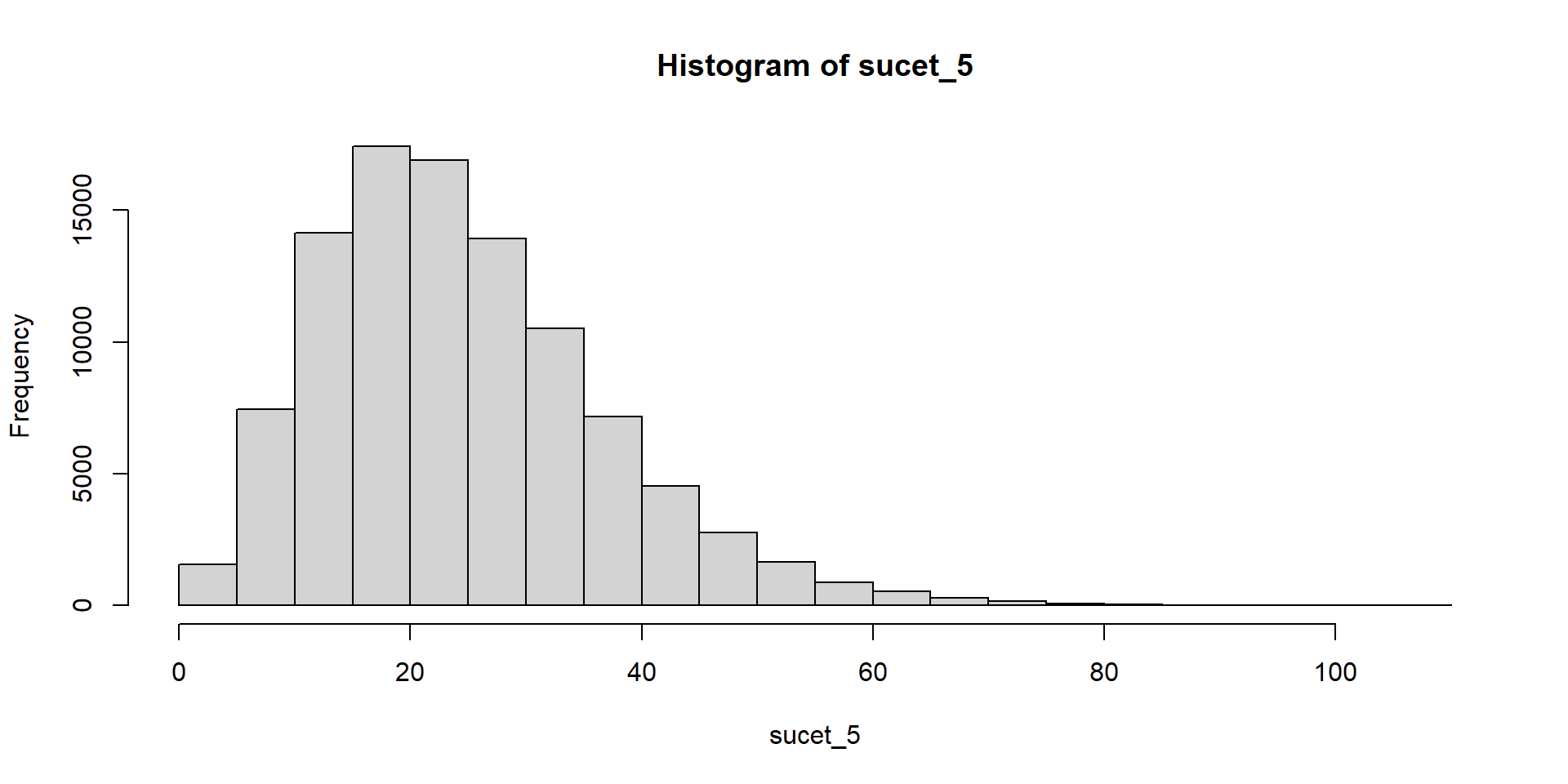
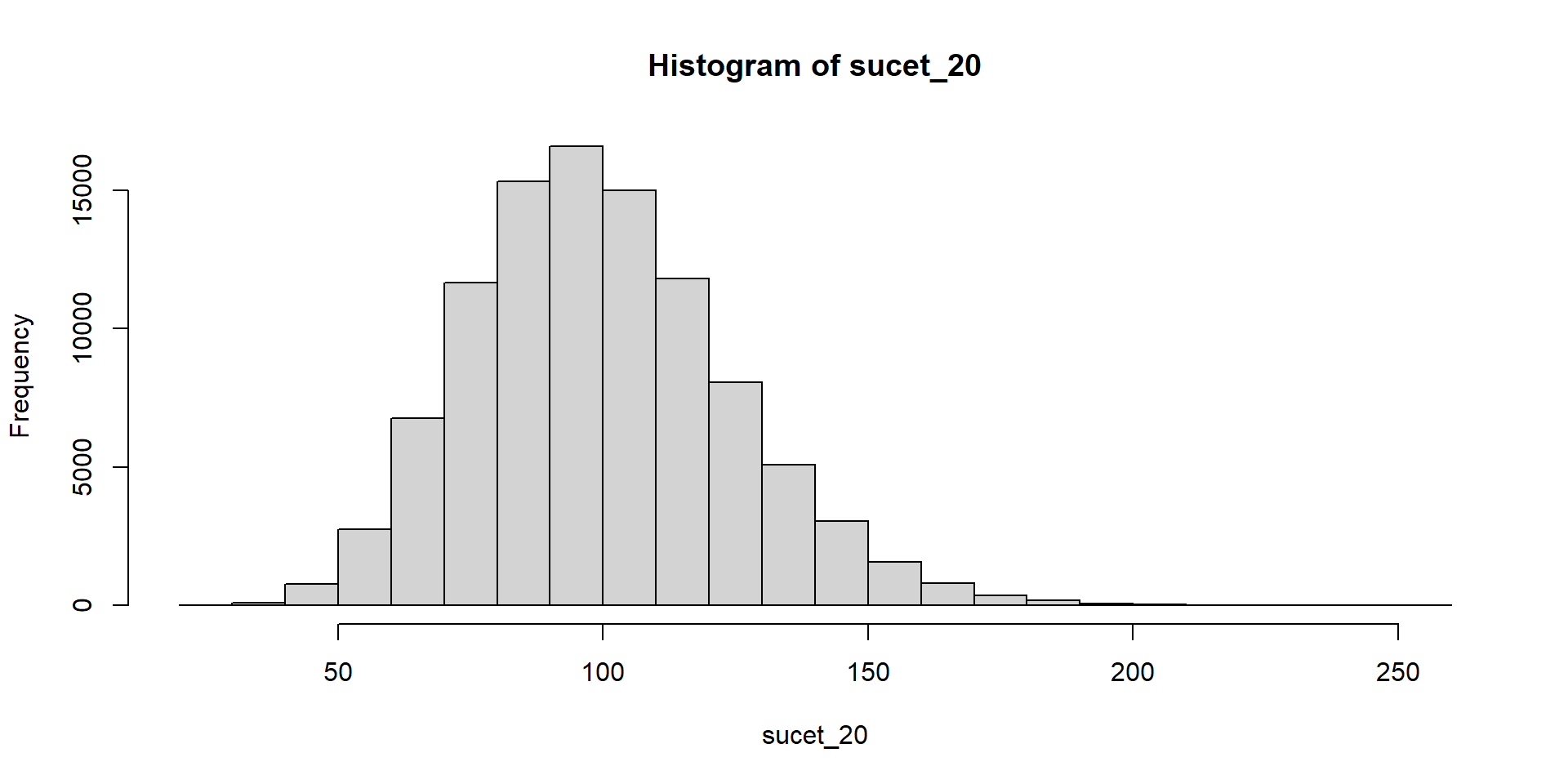
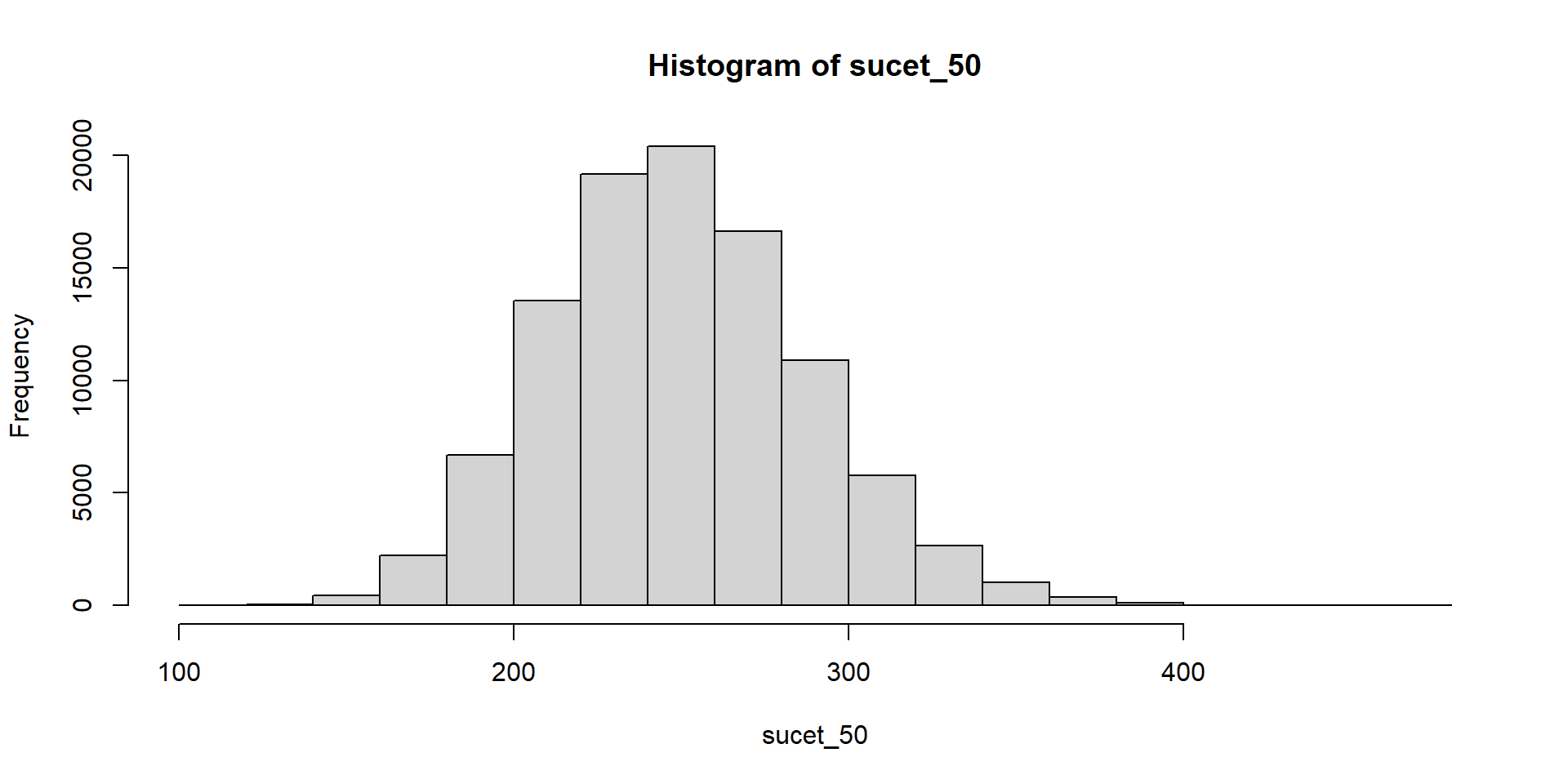
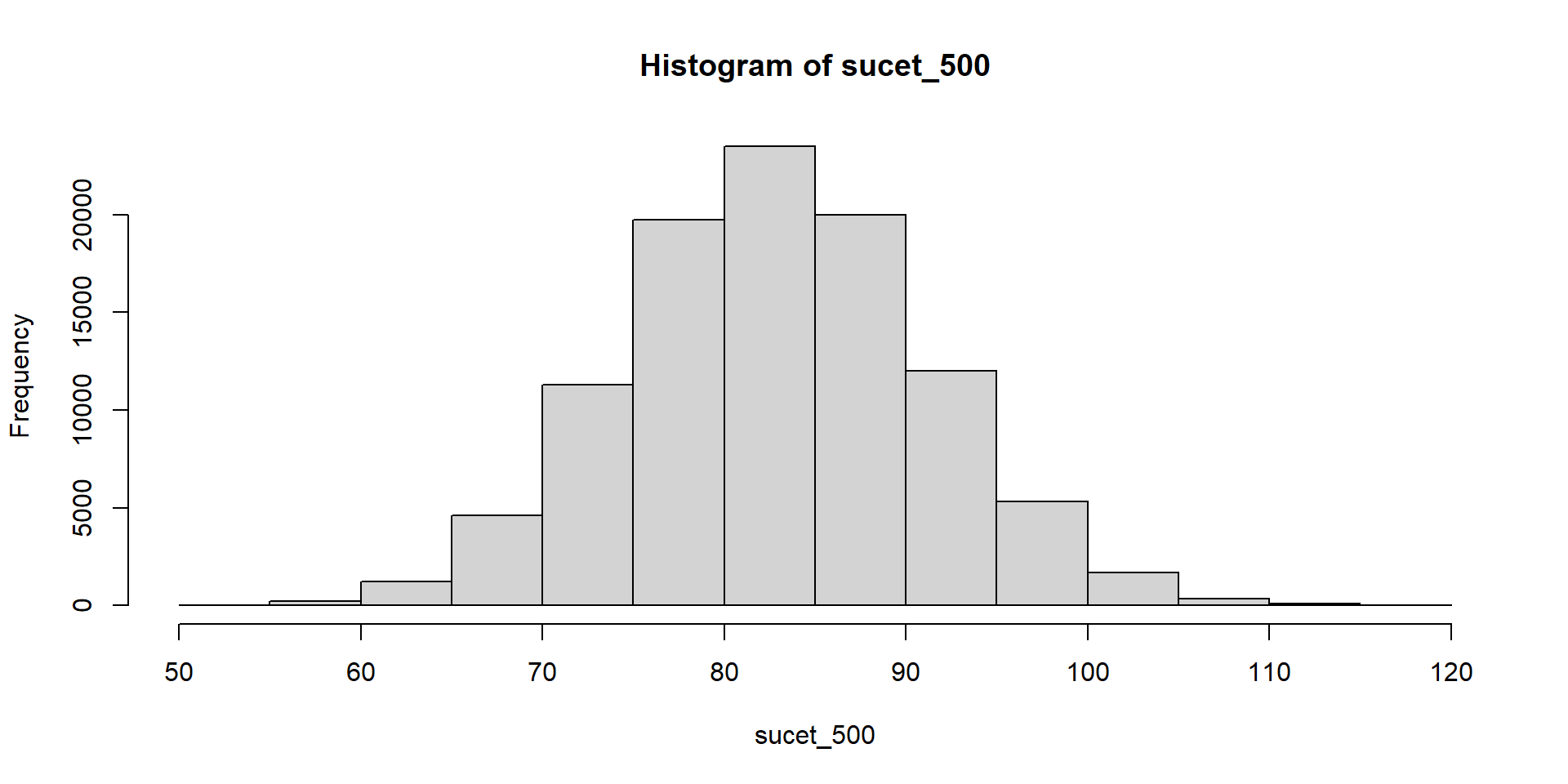
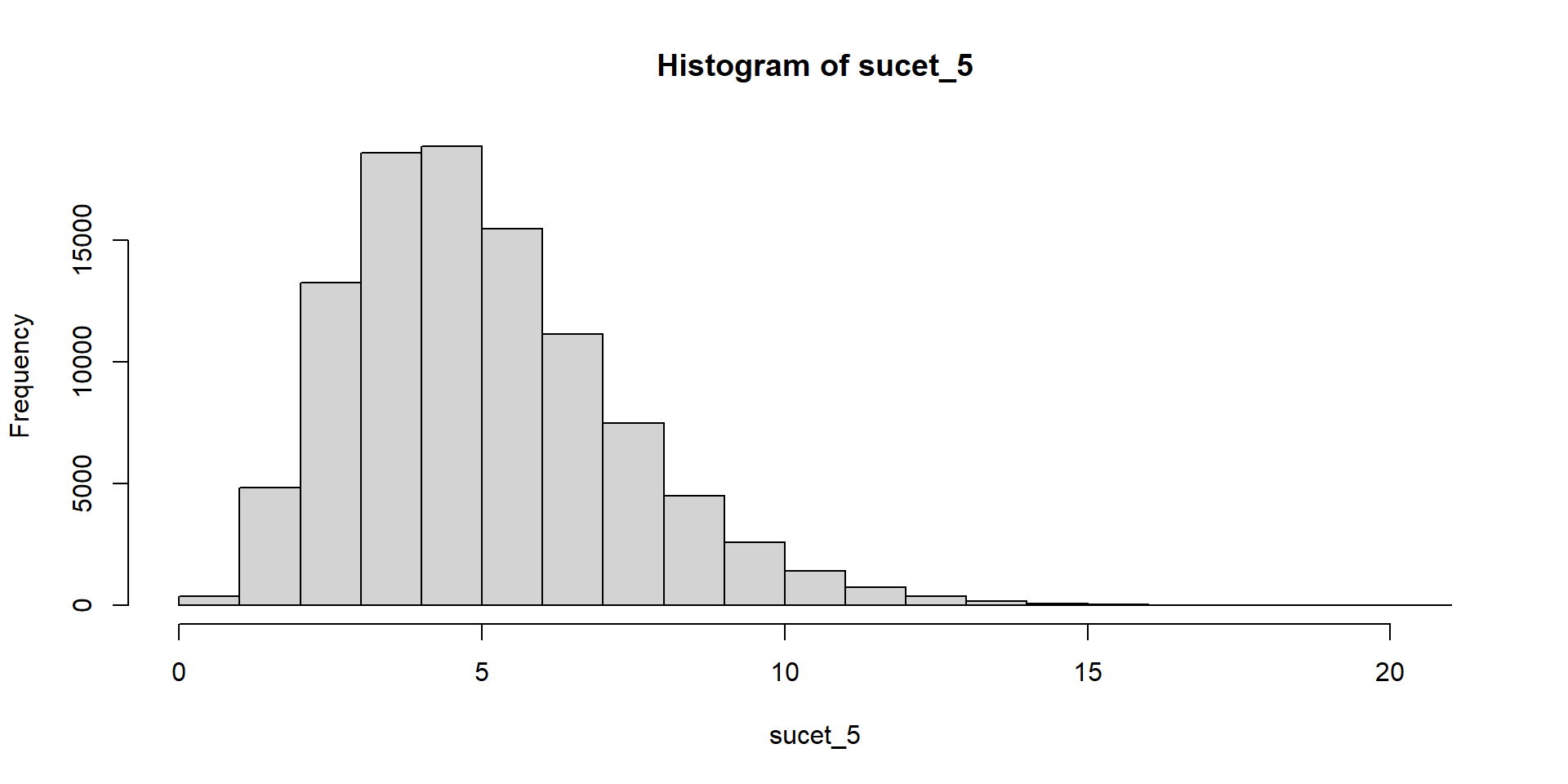
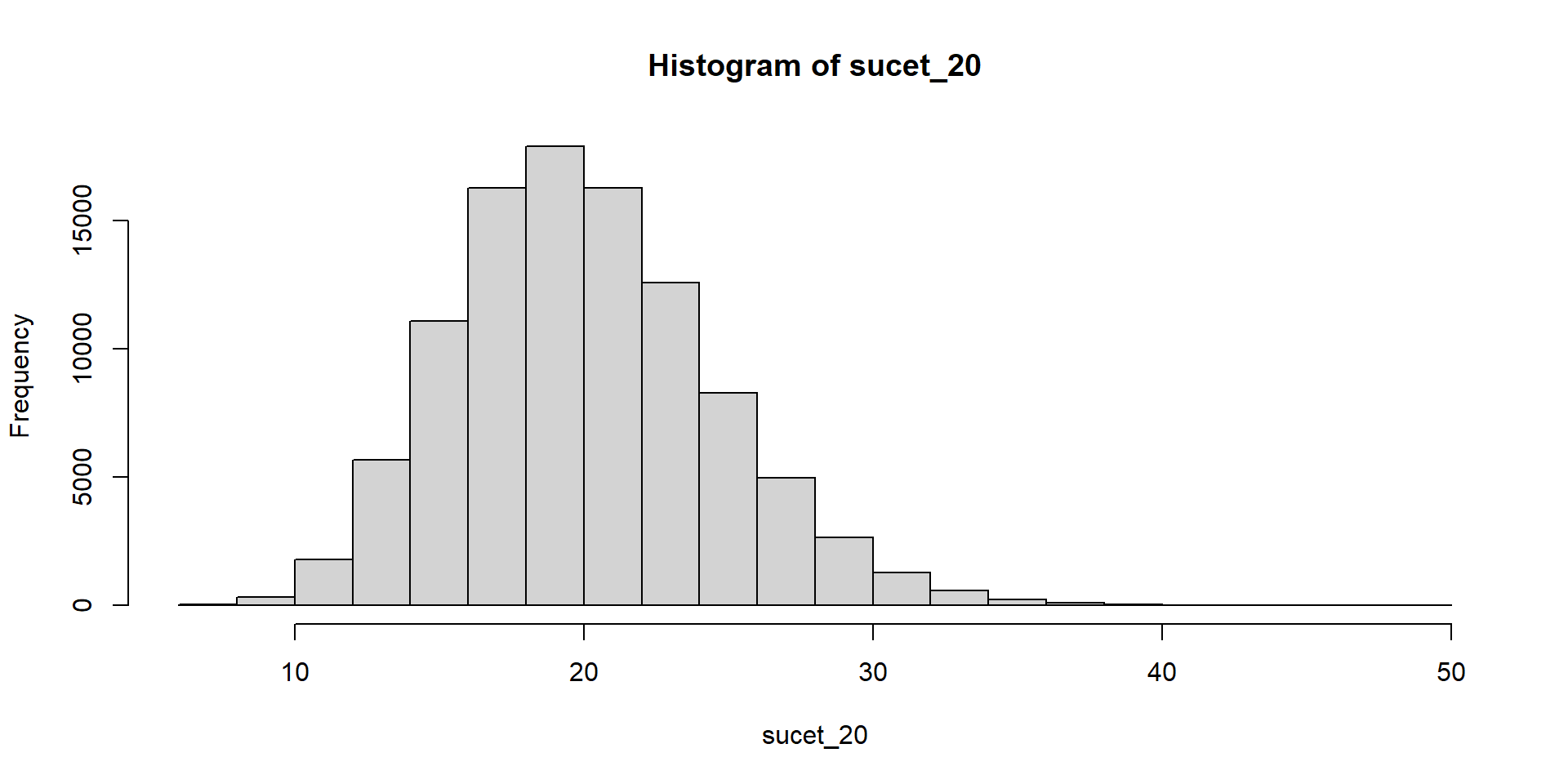
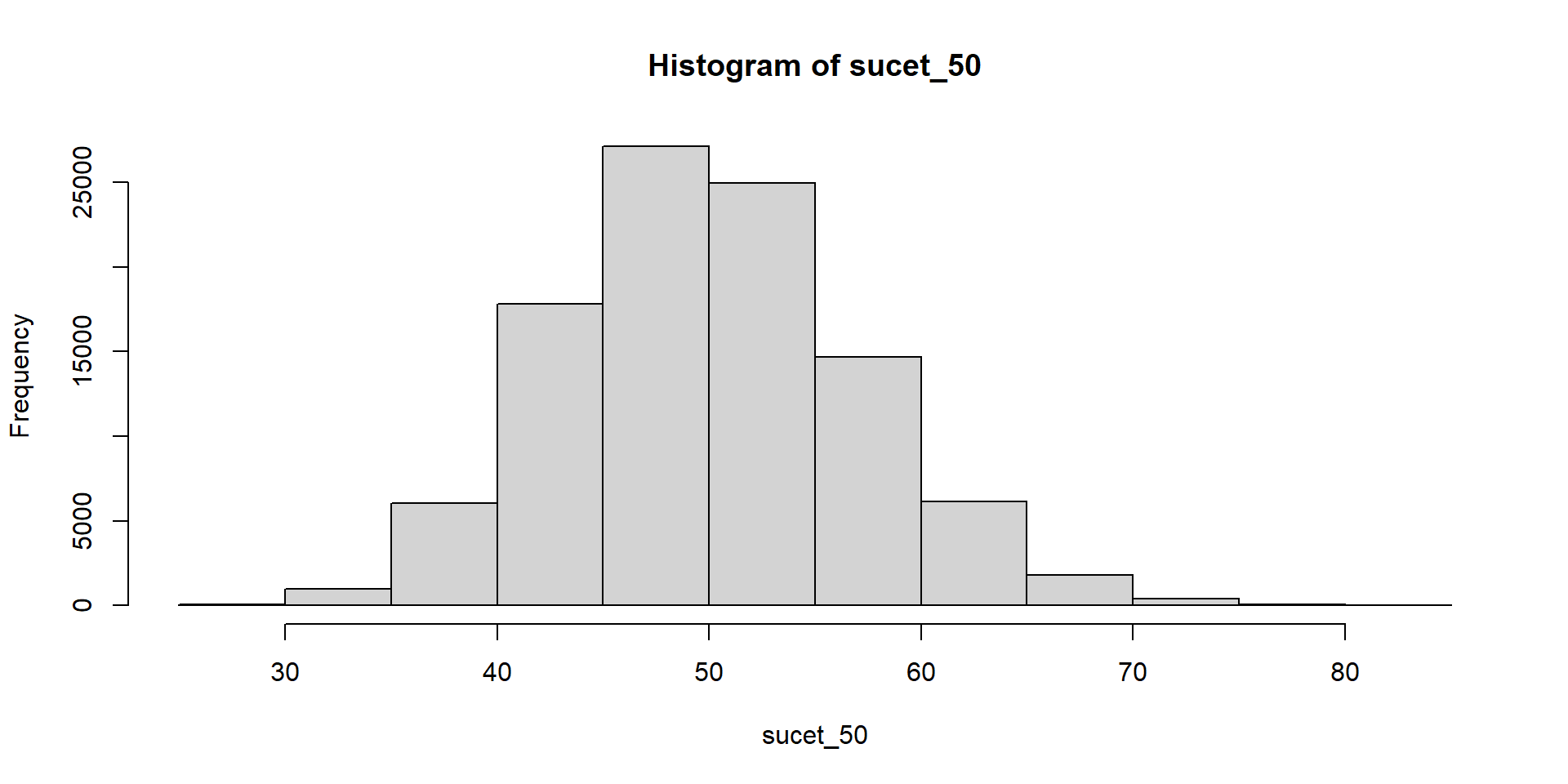
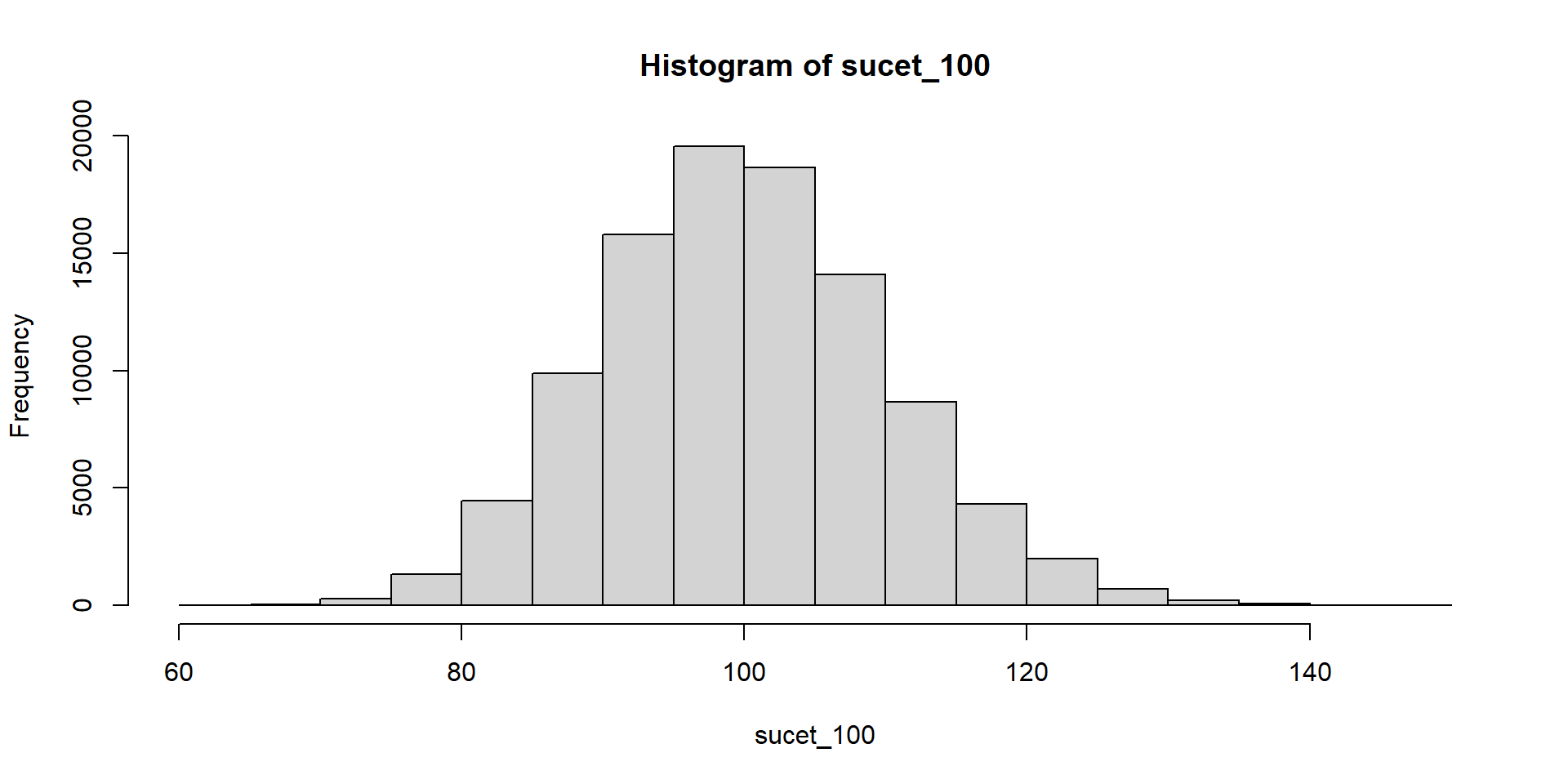
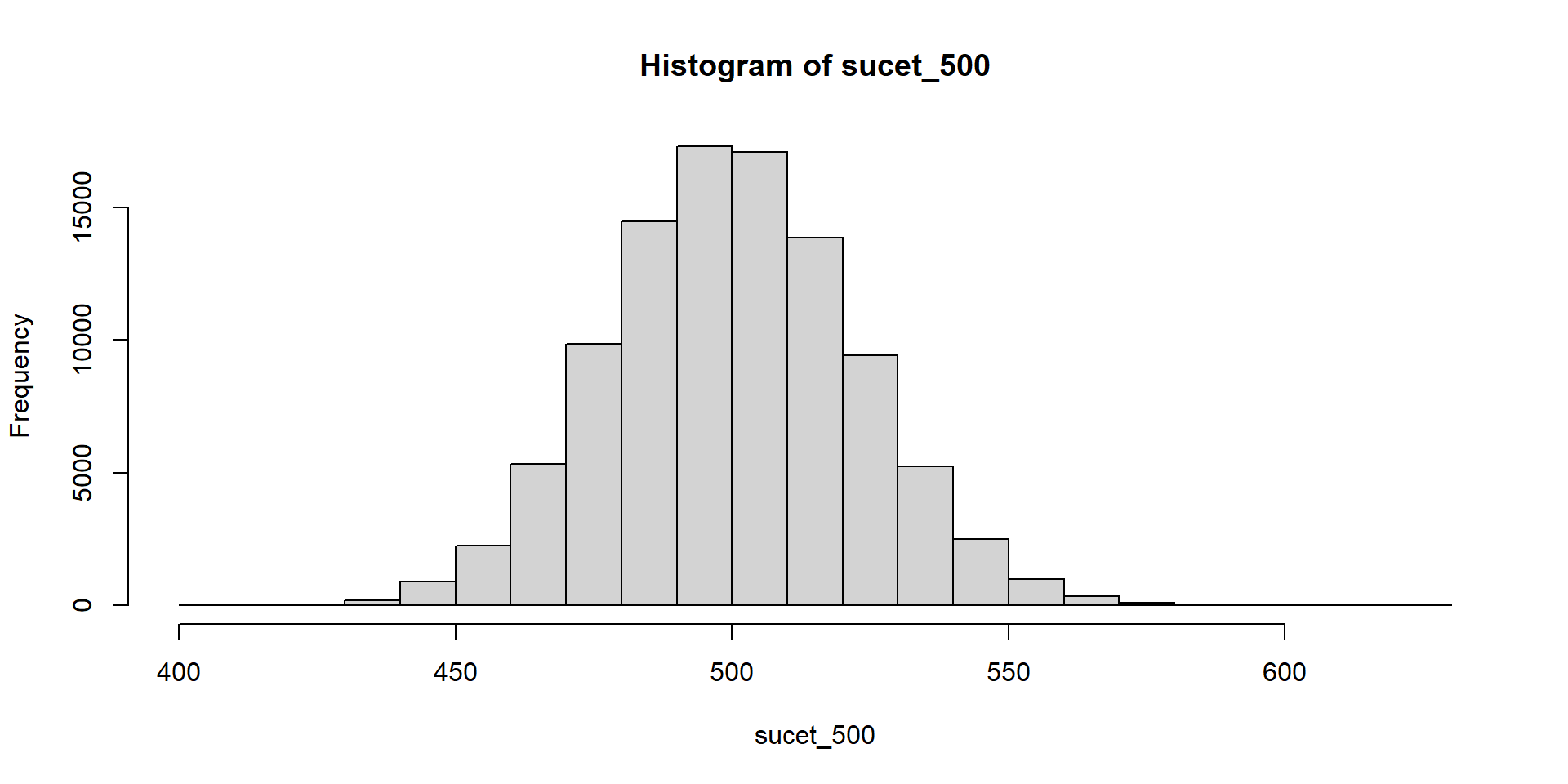
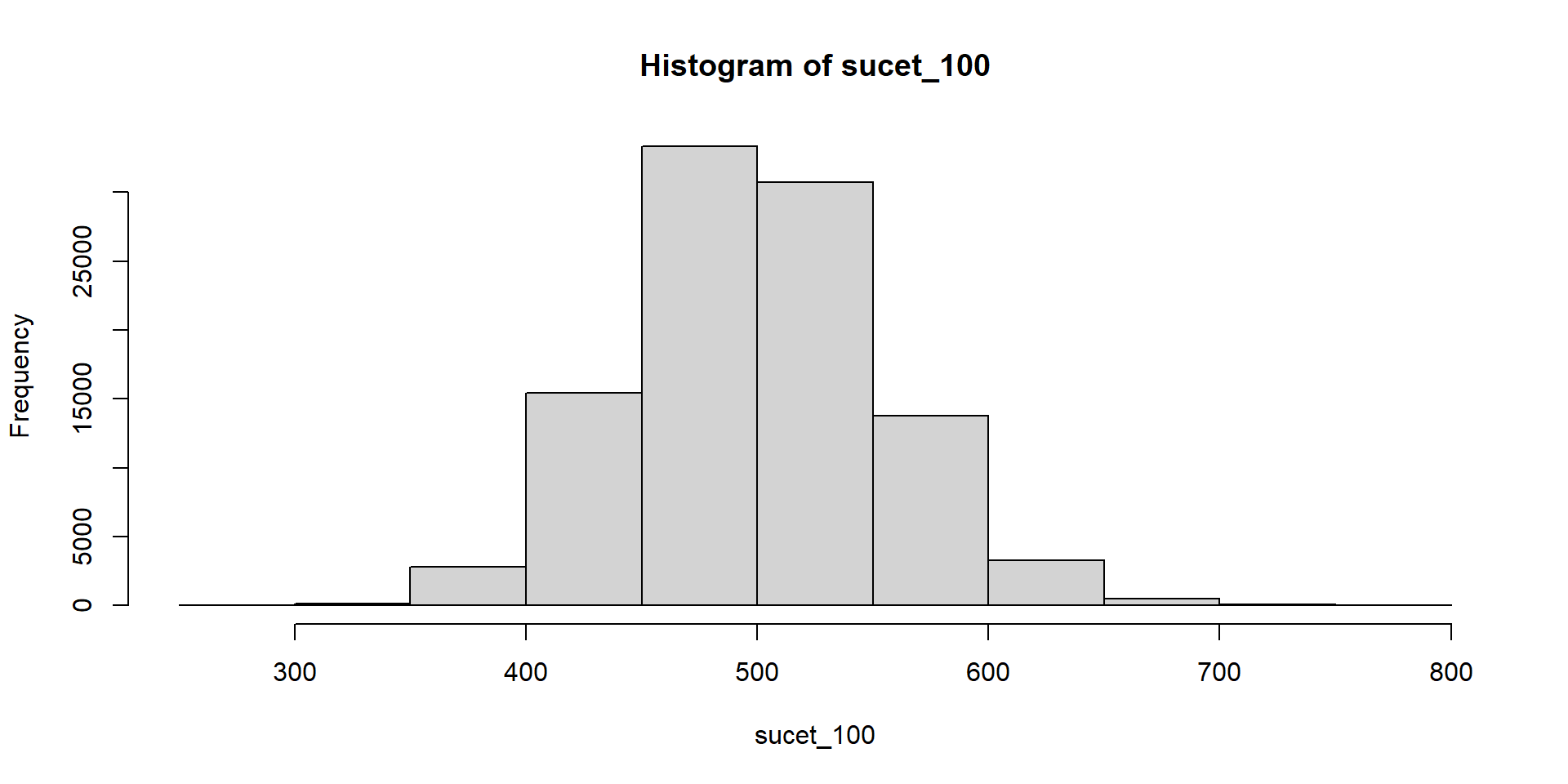Hádžeme kockou a čakáme, kým padne šestka. Zapisujeme počet neúspešných pokusov.
Súčet teda znamená počet neúspešných pokusov pred tým, ako sa dosiahne stanovený počet šestiek.
sucet_geometricke <-function(n, p =1/6){ x <-rgeom(n, prob = p) sucet <-sum(x)return(sucet)}
(3) Exponenciálne rozdelenie
Sledujeme životnosť prístroja, ktorá má exponenciálne rozdelenie so zadanou strednou hodnotou
Súčet teda znamená čas, ktorý nám vydrží zadaný počet prístrojom, ak vždy použivame jeden a po skončení jeho životnosti zoberieme nasledujúci.
sucet_exponencialne <-function(n,ex =1){ x <-rexp(n, rate =1/ex) sucet <-sum(x)return(sucet)}
Centrálna limitná veta
Tvrdenie: Ak \(X_i\) sú nezávislé náhodné premenné so strednou hodnotu \(\mu\) a disperziou \(\sigma^2\), tak pre súčty \(\sum_{i=1}^n X_i\) platí:
\[\frac{\sum_{i=1}^n X_i - n \mu}{\sqrt{n \sigma^2}} \rightarrow \mathcal{N}(0,1)\]
pre \(n \rightarrow \infty\).
Teda: pre veľké \(n\) je
\[\frac{\sum_{i=1}^n X_i - n \mu}{\sqrt{n \sigma^2}} \overset{aprox}{\sim} \mathcal{N}(0,1)\]
\[\sum_{i=1}^n X_i \overset{aprox}{\sim} \mathcal{N}(n \mu, n \sigma^2)\]
To znamená, že pre veľké \(n\) aproximujeme súčet \(\sum_{i=1}^n X_i\) normálnym rozdelením s rovnakou strednou hodnotou a disperziou.
Príklad 1. Pri analýze údajov o zdravotnej starostlivosti bol vek pacientov zaokrúhlený na najbližší násobok 5 rokov. Rozdiel medzi skutočným a zaokrúhleným vekom má rovnomerné rozdelenie of -2.5 do 2.5 rokov. Náhodne sme vybrali 48 pacientov. Aká je približná pravdepodobnosť, že priemer zaokrúhlených vekov je od priemeru skutočných vekov vzdialený nie viac ako štvrť roka?
0.14
0,38
0,57
0,77
0,88
Spravíme:
simuláciu pomocou rovnomerného rozdelenia
výpočet pomocou centrálnej limitnej vety, v ktorej súčet aproximujeme normálnym rozdelením
chyba_priemeru <-function(n =48){ chyby <-runif(n, min =-2.5, max =2.5) chyba_priemeru <-mean(chyby)return(abs(chyba_priemeru) <0.25)}n_sim <-10^5sim_chyba_priemeru <-replicate(n_sim, chyba_priemeru())prop.table(table(sim_chyba_priemeru))
sim_chyba_priemeru
FALSE TRUE
0.23202 0.76798
Distribučná funkcia normálneho rozdelenia (hodnota distribučnej funkcie je pravdepodobnosť, preto p - probability, norm - normálne rozdelenie):
Analogicky distribučná funkcia iných rozdelení (punif, pexp a pod.).
Príklady
Príklad 2. Poisťovňa vydala 1250 poistiek, týkajúcich sa starostlivosti o zrak. Počet nárokov, ktoré poistenec uplatní počas roka, má Poissonovo rozdelenie so strednou hodnotou 2. Predpokladajte, že nároky jednotlivých poistencov sú nezávislé. Aká je približná pravdepodobnosť, že celkový počet nárokov počas roka bude medzi 2450 a 2600?
0,68
0,82
0,87
0,95
1,00
Príklad 3. Polícia prijala 100 policajtiek. Ak zostanú na polícii až do dôchodku, bude im vyplatená dohodnutá suma. Ak budú v tom čase vydaté, rovnakú sumu dostane aj manžek. Je známe:
Pravdepodobnosť, že policajtka zostane do dôchodku, je 0.4.
Ak zostane do dôchodku, pravdepodobnosť, že nebude v tom čase vydatá, je 0.25.
Pre jednotlivé policajtky tieto udalosti nezávisia od ich nastatia/nenastatia u ostatných.
Zaujíma nás počet výplat dohodnutej sumy (policajtkám a manželom). Aká je pravdepodobnosť, že ich nebude viac ako 90?
0,60
0,67
0,75
0,93
0,99
Príklad 4. Hmotnosti bonbónov sú nezávislé, hmotnosť jedného bonbónu v gramoch má rovnomerné rozdelenie na intervale \((9, 11)\). Aká je približná pravdepodobnosť toho, že 100 bonbónov bude mať celkovú hmotnosť menšiu ako 995 gramov?