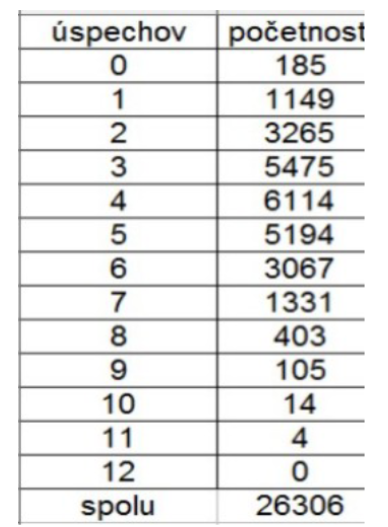
kocky <- c(186, 168, 172, 161, 157, 180)
ocakavane <- rep(1024/6, 6)
statistika <- sum((kocky - ocakavane)^2/ocakavane)
statistika[1] 3.582031Metódy riešenia úloh z pravdepodobnosti a štatistiky
Príklad 1: hádzanie kockou I.

https://www.youtube.com/watch?v=rjYT3WUWq0s
Priebeh:
Z chatu:
Výsledok:

Výsledok jedného hodu je náhodná premenná s hodnotami 1-6, chceme otestovať hypotézu, že pravdepodobnosť každého výsledku je rovnaká.
Použijeme chí kvadrát test dobrej zhody.
Princíp:
kocky <- c(186, 168, 172, 161, 157, 180)
ocakavane <- rep(1024/6, 6)
statistika <- sum((kocky - ocakavane)^2/ocakavane)
statistika[1] 3.582031sim_kocky <- function(n = 1024){
vysledok <- sample(1:6, size = n, replace = TRUE)
vysledok <- factor(vysledok, levels = 1:6)
pozorovane <- table(vysledok)
ocakavane <- rep(n/6, 6)
statistika <- sum((pozorovane - ocakavane)^2/ocakavane)
return(statistika)
}
set.seed(123)
sim_stat <- replicate(10^5, sim_kocky())
hist(sim_stat)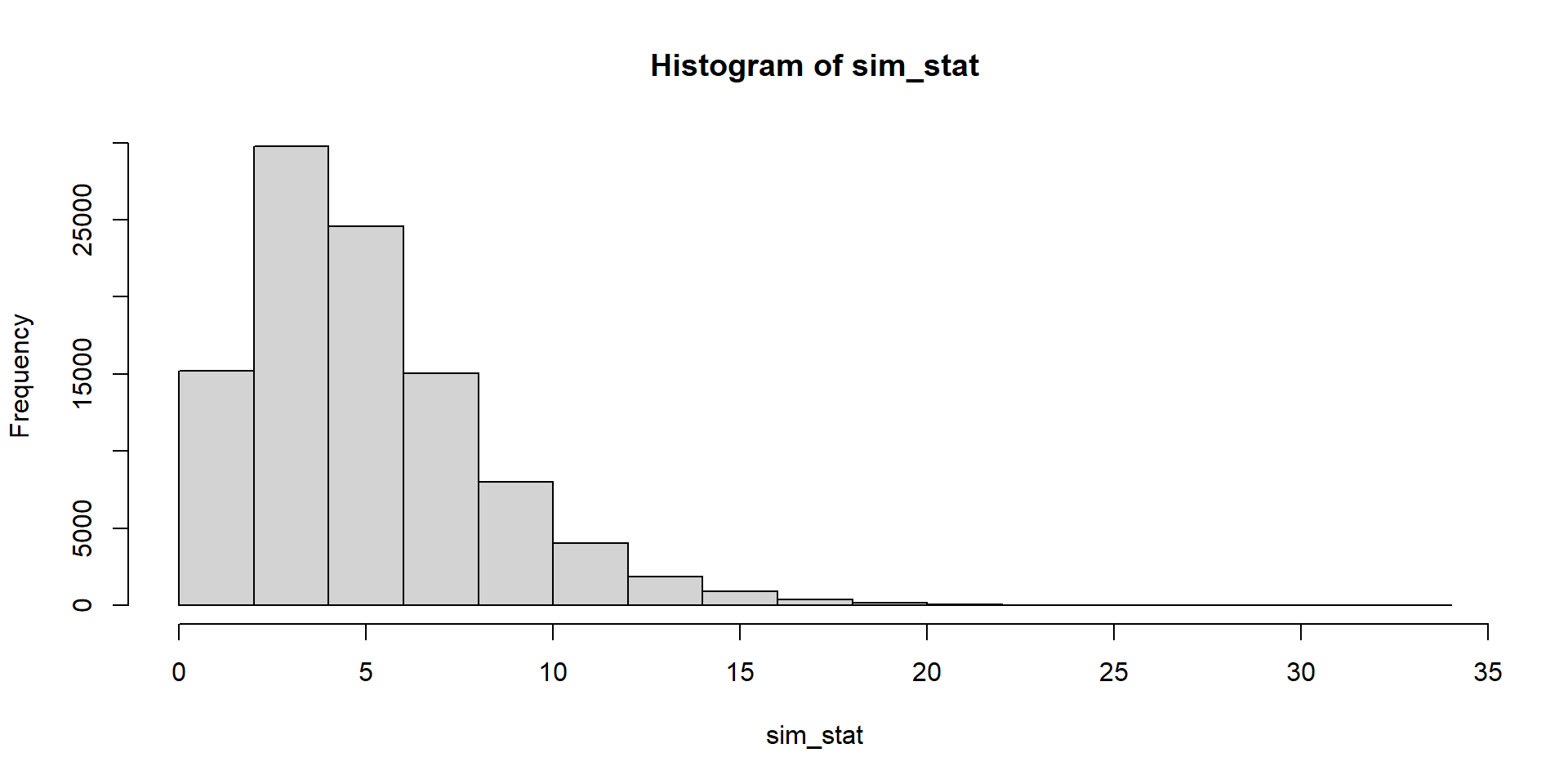
[1] 0.61255Vo viac ako 60 percentách prípadov je štatistika aspoň taká veľká ako naša - nenasvedčuje to tomu, že naše dáta sú veľmi odlišné od očakávaných. Hypotézu o pravidelnej kocke nezamietame.
Príklad 2: hádzanie kockou II.
Budeme sa zaoberať výsledkami, ktoré pri hádzaní kockou získal Walter F. L. Weldon (1860 – 1906). Ten tvrdil, že väčším počtom bodiek pri týchto hodnotách je spôsobená jej nepravidelnosť. Táto nepravidelnosť by mohla byť taká výrazná, že hodnoty 5 a 6 nebudú padať rovnako často ako ostatné. Pri svojich pokusoch hádzal dvanástimi kockami. Ako “úspech” označil padnutie päťky alebo šestky a zaznamenával počet úspechov v jednotlivých pokusoch. Tých spravil spolu 26306 s nasledujúcimi výsledkami:
Ak je minca pravidelná, tak počet úspechov v pokuse má binomické rozdelenie. Otestujeme chí kvadrát testom dobrej zhody, že hodnoty v tabuľke pochádzajú z tohto rozdelenia.
Poznámky:
Kvôli požiadavke na minimálny počet očakávaných úspechov bude potrebné zlúčiť niekoľko posledných riadkov.
Pravdepodobnosti binomického rozdelenia v R sa dajú vypočítať funkciou dbinom.
Pre zaujímavosť: Tieto dáta analyzoval aj Peason, podľa ktorého je tento test dobrej zhody pomenovaný.
Príklad 3 (Bakalárska práca Experimenty a vlastné dáta pri vyučovaní pravdepodobnosti a štatistiky, 2015)
Rozhodli sme sa pozrieť na dĺžku čakania v rade v dvoch študentmi navštevovaných jedálňach v Mlynskej doline, Eat and Meet a Venza. Oslovili sme niekoľko ľudí a požiadali ich, aby si počas jedného týždňa v čase obeda (11:00 - 14:00) merali na stopkách čas od momentu zaradenia sa do radu až po zaplatenie pri kase. V prípade, ak v jedálni rad utvorený nebol, časomiera sa spustila pri uchopení tácky, či prvej súčasti príboru.
Ukážka dát (v sekundách):
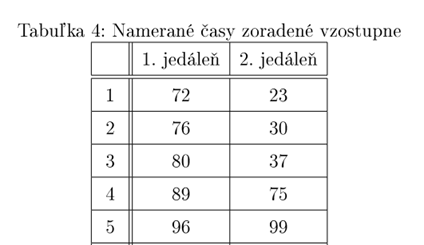
Testovacou štatistikou pre Kolomogorovov-Smirnovov test je maximálny rozdiel medzi distribučnými funkciami odhadnutými z dát. Ak je príliš veľký (väčší ako kritická hodnota), tak sa hypotéza zamietne.
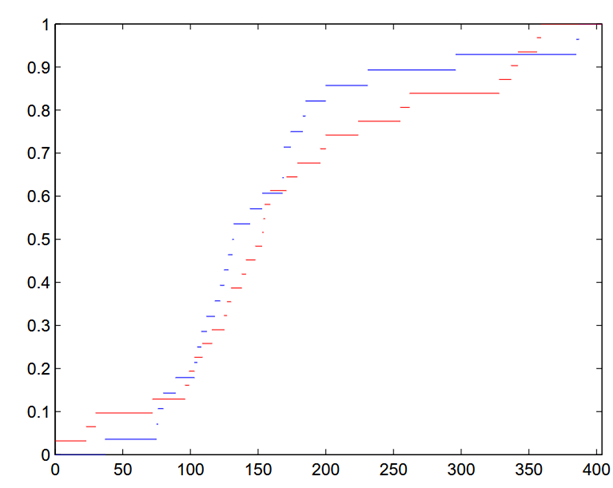
V príklade z BP sa hypotéza o zhode rozdelení nezamietla.
Príklad 4 V jednom z cvičení sa generovali náhodné čísla podľa zadaného algoritmu. Dvaja spolužiaci si chcú porovnať svoje riešenie bez toho, aby si posielali kód. Preto sa rozhodnú porovnať rozdelenie získaných hodnôt. Ak sa ich pravdepodobnostné rozdelenie líši, každý program generuje iné rozdelenie, takže aspoň jeden z postupov je nesprávny. Ak sa rozdelenia zhodujú, budú spokojní, lebo nezávisle od seba by rovnakú chybu asi nespravili.
Otestujeme zhodu rozdelení dát vo vektoroch x1 a x2.
Postup v R: funkcia ks.test