Lineárna a kvadratická diskriminačná analýza
Metódy riešenia úloh z pravdepodobnosti a štatistiky
Opakovanie: viacrozmerné normálne rozdelenie
- Znovu budeme robiť klasifikáciu
- Dáta z troch skupín so známym zaradením do tried
- Predpoklad: dáta z každej skupiny sú z viacrozmerného normálneho rozdelenia
- Dve metódy: v závislosti od toho, či majú rovnaké kovariančné matice alebo nie
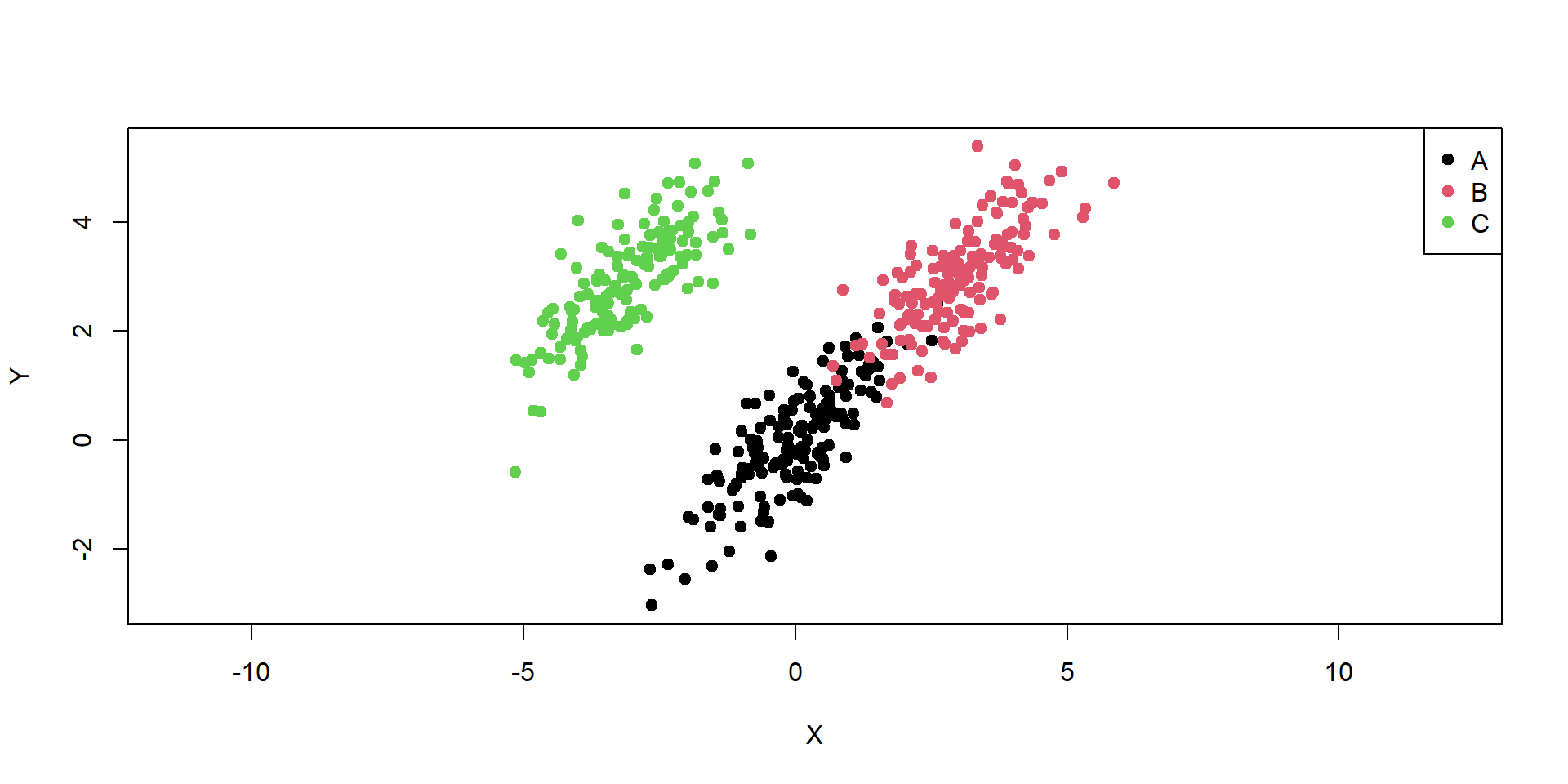
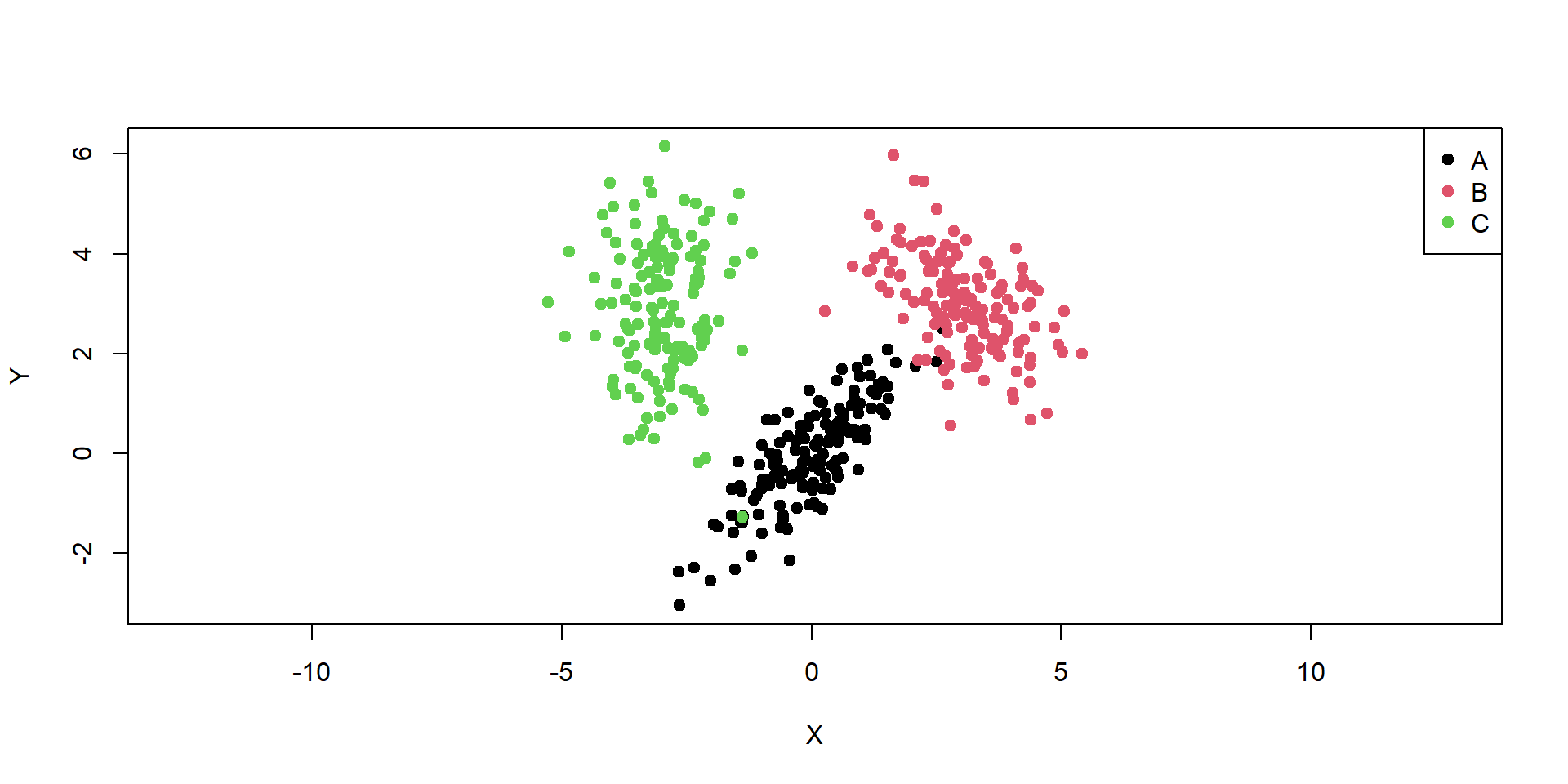
Naše dáta
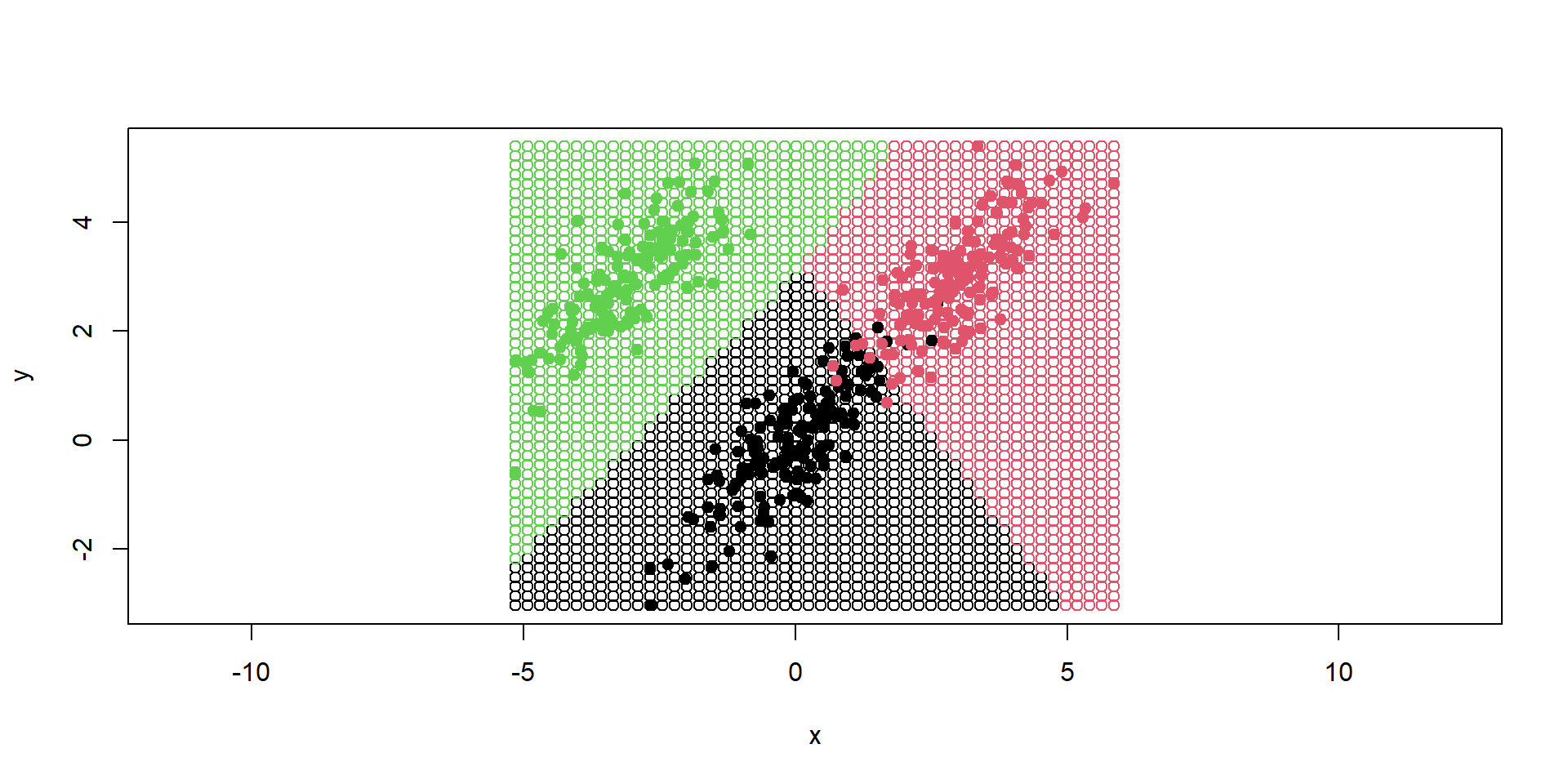
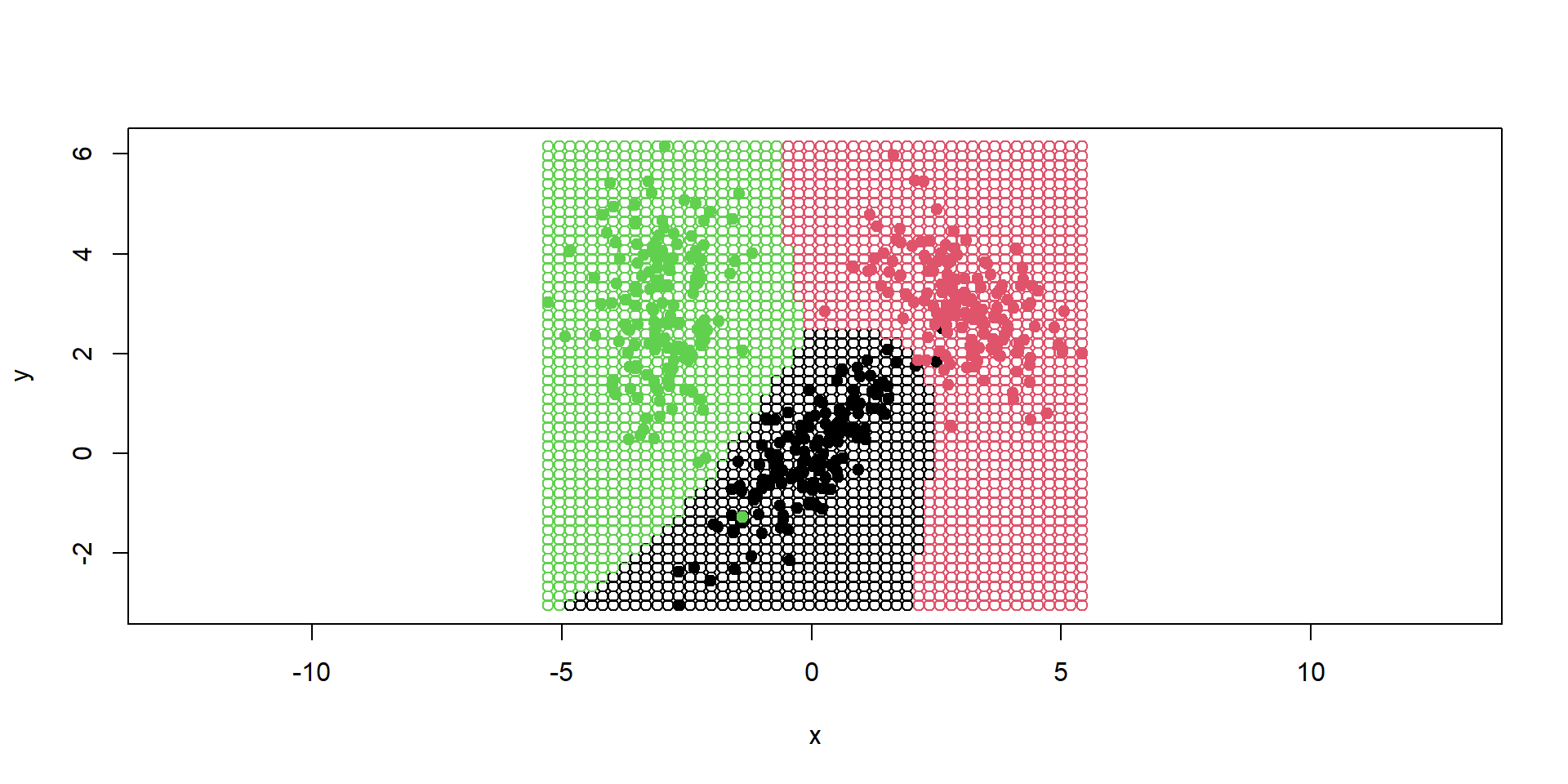
Príklad
Dáta z minulého cvičenia o autách a klasifikácia na základe spotreby:
data("mtcars")
mtcars$mpg_nadpriemer <- (mtcars$mpg > mean(mtcars$mpg))
mtcars$mpg_nadpriemer <- factor(mtcars$mpg_nadpriemer)
library(caret)
set.seed(123)
mtcars_index <- createDataPartition(mtcars$mpg_nadpriemer,
p = 0.8, # podiel dat v trenovacej casti
list = FALSE)
# indexy testovacej casti
(1:nrow(mtcars))[-mtcars_index][1] 4 8 13 14 31Teraz zoberieme spojité premenné, budeme predpokladať, že predpoklad normality je splnený:
plot(mtcars_train$wt, mtcars_train$qsec,
xlab = "wt", ylab = "qsec",
col = c("red", "blue")[as.numeric(mtcars_train$mpg_nadpriemer)], pch=19)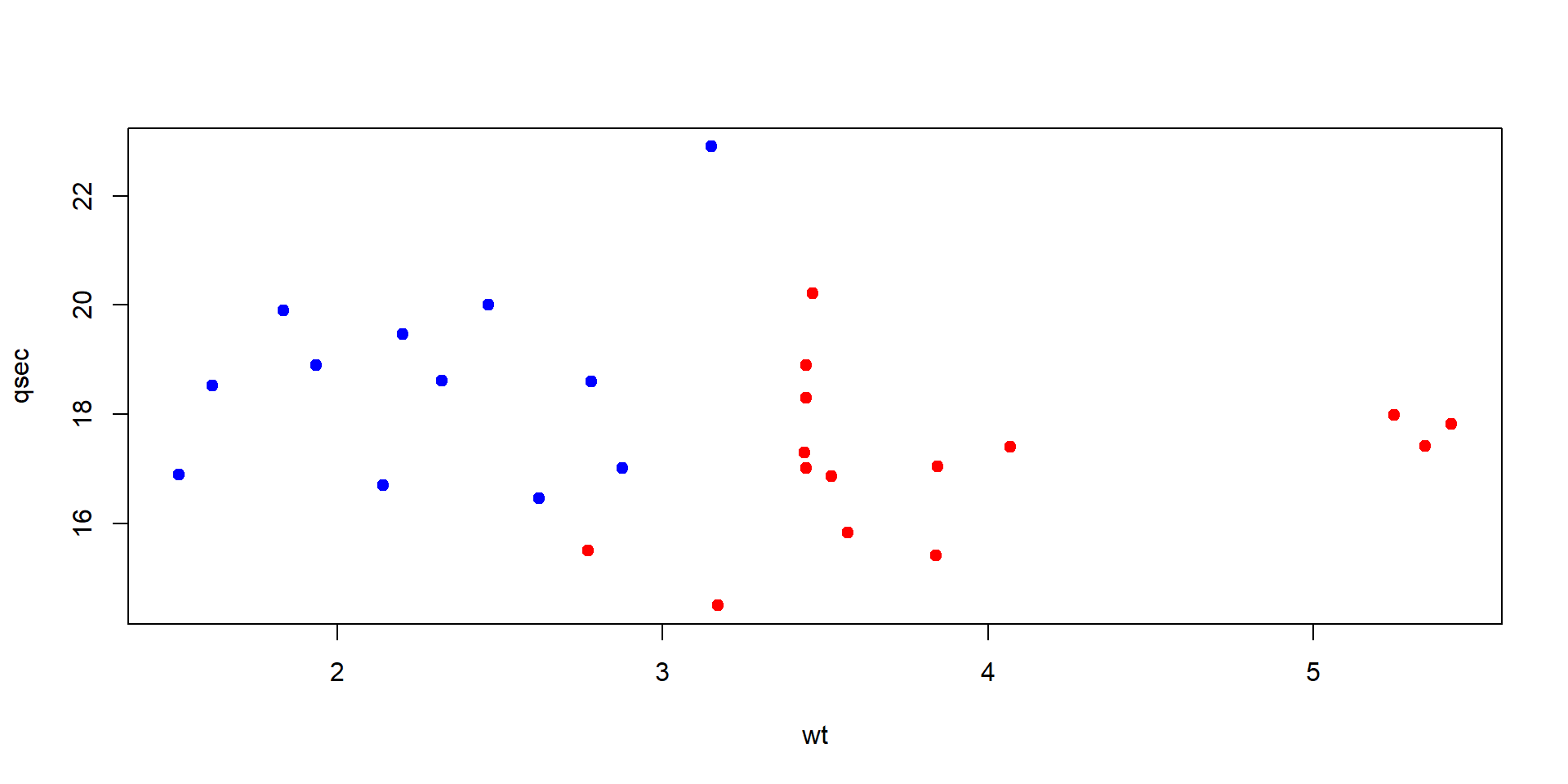
Spolu s dátami (čierne), ktoré chceme predikovať:
plot(mtcars_train$wt, mtcars_train$qsec,
xlab = "wt", ylab = "qsec",
col = c("red", "blue")[as.numeric(mtcars_train$mpg_nadpriemer)], pch=19)
points(mtcars_test$wt, mtcars_test$qsec, col = "black", pch = 19)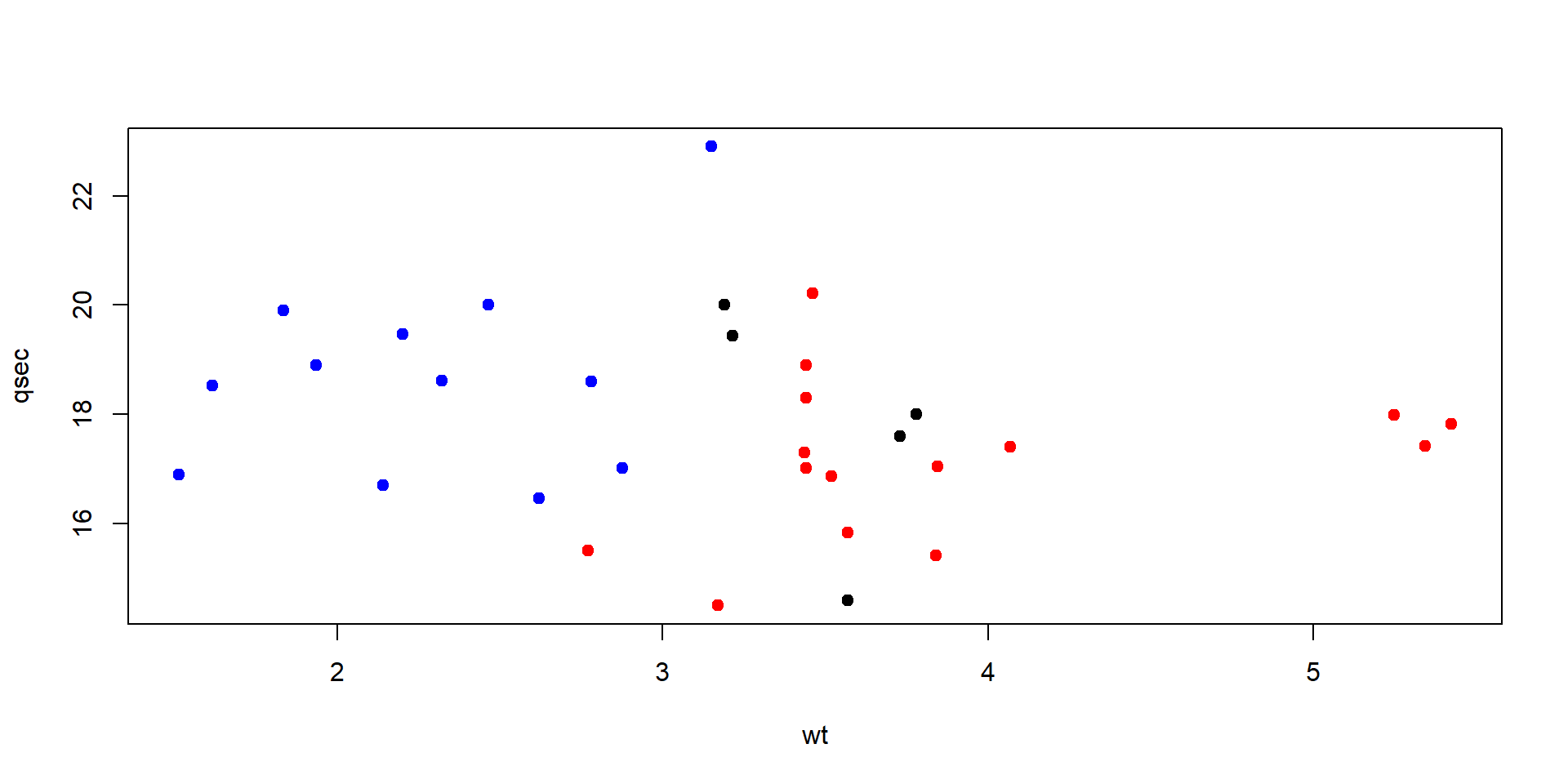
Kvadratická diskriminačná analýza a predikcie:
Call:
qda(mpg_nadpriemer ~ wt + qsec, data = mtcars_train)
Prior probabilities of groups:
FALSE TRUE
0.5555556 0.4444444
Group means:
wt qsec
FALSE 3.867933 17.16867
TRUE 2.287333 18.66583[1] TRUE TRUE FALSE FALSE FALSE
Levels: FALSE TRUE FALSE TRUE
Hornet 4 Drive 0.4064068 0.593593185
Merc 240D 0.2125211 0.787478891
Merc 450SL 0.9935647 0.006435312
Merc 450SLC 0.9926888 0.007311209
Maserati Bora 0.9985874 0.001412613Realita: